MRC - Open Domain Question Answering
청계산셰르파의 MRC-ODQA 등반일지

약 4주가량 참여했던 P Stage 의 MRC - Open Domain Question Answering 대회를 Wrap up 하였습니다. 청계산 셰르파의 일원들과 두 번째 합을 맞추었고, 어설픈 점도 많았지만 어떤 마음가짐과 전략으로 대회에 임했으며 서로가 서로의 셰르파 로써 등반을 완료할 수 있었는지 저희의 경험을 나누고자 합니다.
미흡한 점도 있었고, 여러 시행착오를 겪었지만 KLUE - RE 대회보다 2계단 상승한 3위를 달성할 수 있었습니다. 다양한 문제를 인식하고 해결하기 위한 아이디어를 수집한 뒤 결과적으로 구현하며 좋은 성과를 이루어낼 수 있었다는 점에서 팀원 모두가 많은 성장을 했다고 느낄 수 있었습니다. 언제나 그렇듯이, 저희의 경험이 어떠한 형태로든 도움이 되고 좋은 레퍼런스가 되기를 바라며 시작해보도록 하겠습니다.
팀 소개
청계산셰르파


저희는 캠프 기간동안 모든 것을 생생하게 기억하고 나누는 기록과 공유라는 가치에 공감한 7명이 모여 팀을 구성했고, 서로가 서로의 가이드로서 좋은 영향을 주고받을 수 있는 셰르파가 되기를 원했습니다.
또한 주니어 엔지니어들의 로망은 판교역 근처 회사들에서 일을 하는 것입니다. 저희는 판교역의 뒷산인 청계산을 부스트캠프 과정에 빗대어 완벽하게 등반해보겠다는 의미로 청계산과 셰르파를 더해 청계산셰르파라는 이름을 사용하게 되었습니다.
청계산셰르파들
-
이요한
-
문하겸
-
전준영
-
정진원
-
김민수
-
정희영
-
곽진성
대회 소개
Question Answering (QA) 은 다양한 종류의 질문에 대해 대답하는 인공지능을 만드는 연구 분야입니다. 다양한 QA 시스템 중, Open-Domain Question Answering (ODQA) 은 주어지는 지문이 따로 존재하지 않고 사전에 구축되어 있는 Knowledge resource 에서 질문에 대답할 수 있는 문서를 찾아 질문에 대한 답을 하는 과제로 일반적인 QA 보다 Challenging한 과제입니다.
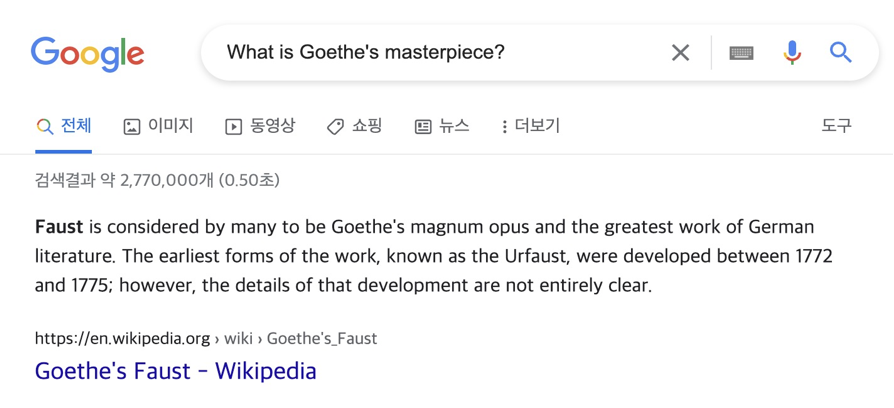
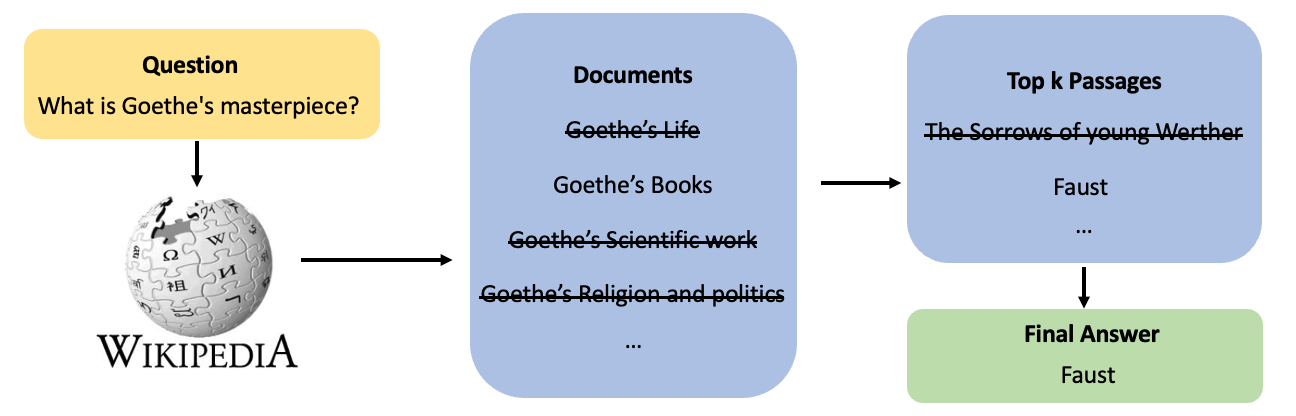
대표적인 ODQA 시스템의 예시로는 Google 검색엔진이 있습니다. Google에 질문을 입력하게 되면 Wikipedia 등에서 Knowledge Resource에서 질문에 답을 할 수 있는 Retrieval이 동작하여 관련 문서를 찾고, Reader가 그 문서 속에서 정답을 찾아 답을 알려주는 시스템입니다.
이번 대회는 이 ODQA 시스템 중 질문과 관련있는 문서를 찾아주는 Retrieval과, 관련된 문서 중에서 적절한 답변을 찾는 Reader의 두 가지 stage를 구현하고 통합하여 정확한 답변을 많이 내주는 모델을 만드는 대회였습니다.
저희 팀은 4주동안 175회라는 다른 팀 대비 압도적인 제출횟수를 기록하며 굉장히 많은 실험을 이어갔고, 최종적으로 Private Leaderboard에서 3위를 기록하였습니다.Strategy & Planning
이번 대회는 4주라는 긴 시간동안 진행되었기 때문에, 그 시간들을 헛되이 쓰지 않게 하기 위해서는 적절한 대회전략을 세울 필요가 있었고, 그에 걸맞는 계획을 수립해야 했습니다.
이번 대회에는 아래와 같은 제약사항이 있었습니다.
- 외부 dataset 사용 금지.
- Pretrained Model weights의 경우 상업적 이용이 가능한 License를 가지고 있으며 누구에게나 공개된 모델이어야 함.
- Reader Model을 학습시키는 것이 아닌, 제공된 학습 Data를 Generation Model 등을 이용하여 Augmentation 시키는 것을 목적으로 한다면 상업적 이용이 불가능하더라도 Pretrained Model Weights 사용 가능.
지금까지의 경험과 위의 제약사항들을 토대로 보다 strict 하게 계획을 세우기로 하였고, 아래의 Timeline 대로 작업을 진행하기로 했습니다.
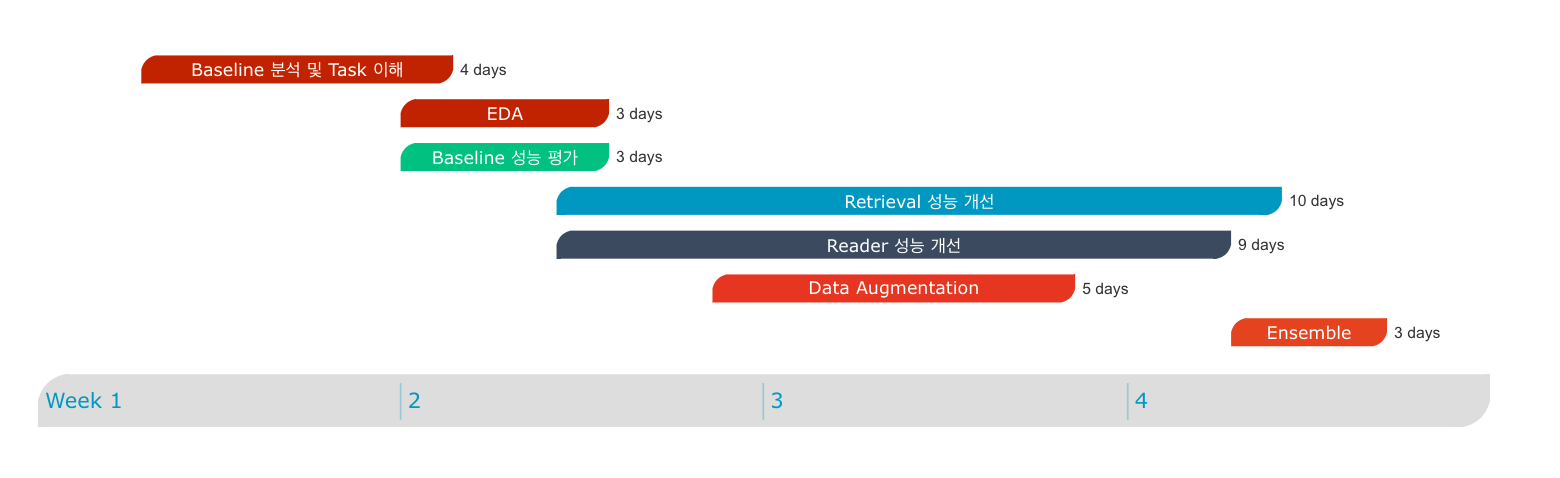
첫 1주차에는 주어진 baseline 코드가 어렵게 작성되어 있었기 때문에 MRC라는 Task에 대한 공부를 바탕으로 baseline 코드 분석 및 refactoring을 진행했습니다. 2주차부터 본격적으로 EDA와 성능평가를 기반으로 baseline 의 어떤 부분을 보완하면 성능을 향상시킬 수 있을지를 집중적으로 탐색해보았습니다. 그리고 그렇게 탐색한 결과를 바탕으로 3주차에는 data augmentation 과 retrieval, reader 의 성능을 향상시키기 위한 아이디어들을 실제로 구현하고 실험하며 성능을 최대한 끌어올렸고, 그렇게 얻은 모델들을 마지막 4주차 때 앙상블하여 최종 결과를 도출했습니다.
Baseline 분석 및 Task 이해, Refactoring
베이스라인 코드를 훑어보고 분석하는 과정에서 상당한 난항을 겪었습니다. “적어도 실행은 된다!” 라는 측면에서는 완전한 형태로 제공되었지만, 다른 두 번의 대회와 다르게 내부 Process 가 복잡하고 대체로 경험이 있었던 분류 과제보다는 난이도가 어려웠기 때문입니다.
하지만 자유로운 실험과 Customizing 을 위해서는 개념적으로만 대략적으로 이해하고 있었던 ODQA Task 가 실제 코드로 어떻게 구현되었는지 보다 자세히 파악하는 동시에 저희가 편하게 사용할 수 있도록 Refactoring 을 진행하면서 필요한 모듈을 적용시키는 과정이 필요했습니다. 이 과정에서 셰르파의 일원인 김민수 캠퍼님이 굉장한 수고와 기여를 해주셨습니다.
기존 베이스라인 코드
코드를 살피고 프로세스를 익히면서 처음에 아래와 같은 생각을 하게 되었습니다.
1. 코드의 가독성이 정말 좋지 않다는 것
2. 처음부터 저희의 입맛대로 작성하는 것이 차라리 더 쉽지 않을까
베이스라인의 train.py 스크립트를 살펴보았을 때, 해당 코드의 간략한 구조는 아래와 같습니다.
1 | |
베이스라인 run_mrc 함수는 Preprocess 와 Postprocess, Compute Metrics 등의 함수를 정의하고 실행하며, 학습까지 시작시키는 여러 책임을 가지고 있는 함수였습니다. 이렇게 많은 작업들이 수행되는데, 이 작업들이 nested function 형태로 함수화되어 있었습니다. 이로인해 run_mrc의 구조가 한 눈에 보이지 않았고 각 nested function의 내용을 파악하는 것이 굉장히 힘들었습니다.
또한 위의 이유와 더불어 nested function은 그 특성상 run_mrc 상에서 정의된 변수, 객체 등에 접근할 수 있는데, 이로 인해 어떤 변수나 객체 등이 어느 nested function 안에서 변하거나 변하지 않았는지에 대해 파악하는 것에 어려움이 있었습니다. 그리고 이러한 nested function 이 Huggingface Trainer 내부에서 동작해야하기 때문에 train.py 와 inference.py 등의 스크립트에서도 중복으로 존재했으며 Debugging 을 위해서는 Huggingface 의 코드들을 일일이 덧붙여가며 확인해야 했습니다.
재구성한 베이스라인 코드
이러한 문제점들을 인식한 뒤, huggingface 와의 호환성을 유지하며 학습 과정에 쓰이는 입력과 출력 형식을 Customizing 하기 위해 huggingface의 Trainer 클래스를 상속받아 본인만의 Custom Trainer 클래스를 작성하고, 이를 통해 학습을 진행하도록 코드를 재구성하였습니다. 하지만 문제는 Custom Trainer 클래스를 작성하며 이미 존재하는 몇몇 method 를 task에 맞게 새로 작성하여 덮어씌웠는데,
이 과정에서 Huggingface 와 의존성이 존재하는 코드들을 대부분 제외시켰다는 것에 있었습니다. 이렇게 작성된 코드는 향후 다양한 실험을 진행할 때 방해요소가 되겠다는 생각을 하였으며, Task specific 한 방식으로 구성하는 것보다는 미리 라이브러리와의 호환성 문제를 최소화하는 방향으로 코드를 재작성하는 것이 좋겠다는 판단을 하게 되었습니다.
최종적으로 사용된 구조는 아래와 같습니다.
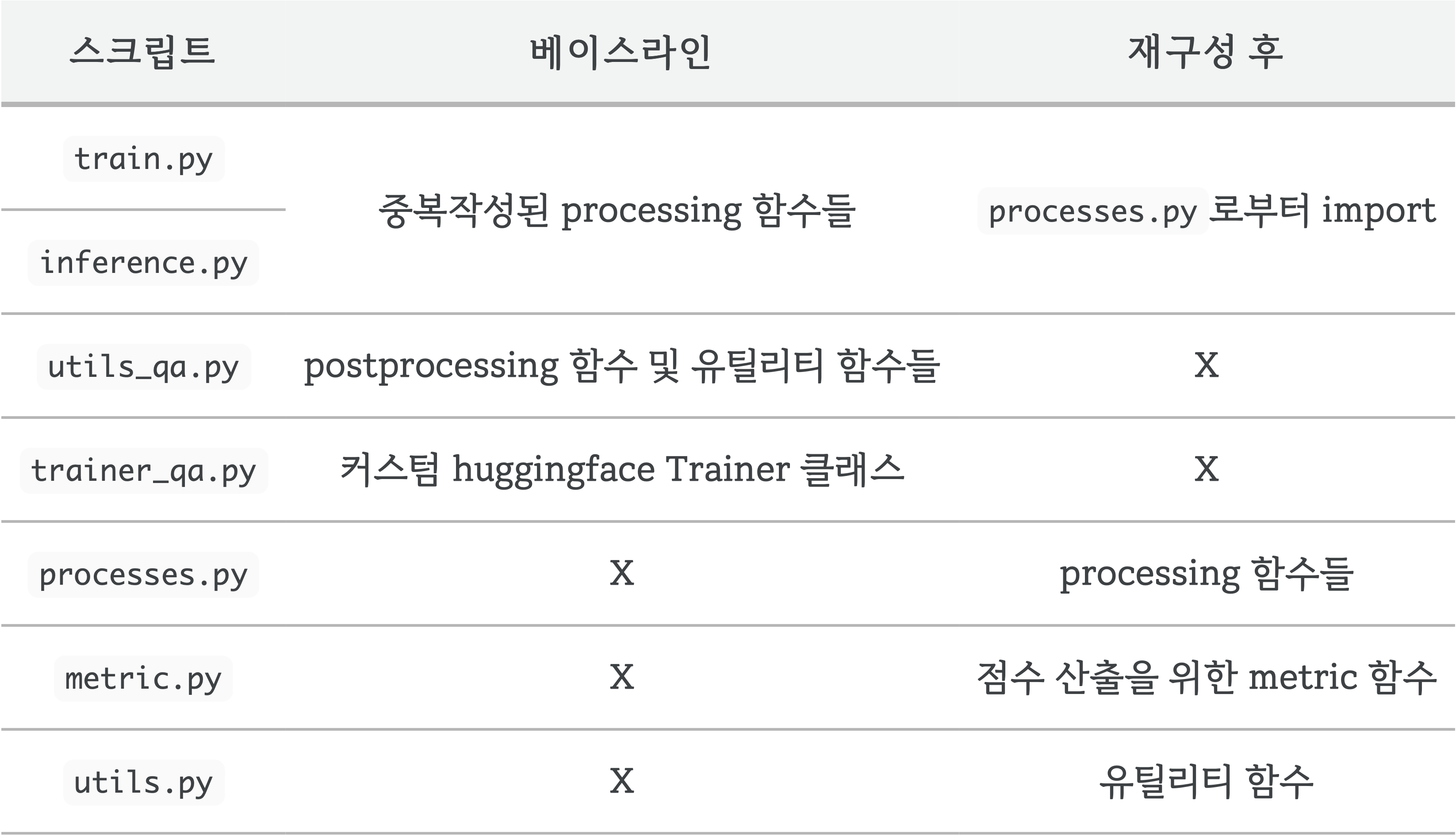
위에서 언급했던 문제를 해결하기 위해 postprocessing 과정을 변경하였으며, huggingface의 기본 Trainer를 사용해 학습할 수 있도록 하였습니다. 이렇게 구성된 train.py 는 아래와 같습니다.
1 | |
하지만 베이스라인 코드의 의도를 몰라봤을 수도 있고, 이상하게 해석했을 여지가 남아있습니다. 그럼에도 나름대로 제공된 베이스라인 코드를 분석해보며 새롭게 reproduction 한 것에 의의를 두게 되었습니다.
이 과정을 통해 ODQA Task 가 어떻게 이루어지는지 Scratch 부터 파악할 수 있었으며, 모델의 input 부터 추론과 Metric 은 물론 output 까지 명확히 파악할 수 있었습니다.
Data

주어진 학습 데이터의 샘플은 3,952개로 매우 적은 양이었습니다. 사전학습된 모델로 Fine-tuning을 진행했을 때 쉽게 Overfitting이 일어날 거란 판단을 하게 되었고, Augmentation에 집중하여 좀 더 Robust한 모델이 될 수 있도록 하고 다양한 Augmentation들을 진행한 후 모델에 쉽게 공급하기 위해서 해당 파이프라인을 구축하는 것에 집중할 수 있도록 계획을 세웠습니다.
이후에는 Retrieval과 Reader 두 가지 성능이 모두 중요했기 때문에 성능을 올리기 위한 방법을 찾고 구현하는 쪽에 집중하며, 최종적으로는 다양한 Ensemble을 통해 모델의 성능을 극대화시키고자 했습니다.
Retrieval
Retrieval은 질문에 맞는 문서를 찾는 것을 뜻합니다. Retrieval 을 수행하기 위해서는 질문에 대한 문서들의 Rank 를 계산해야하는데, 이를 위해서 질문과 문서를 Embedding 해야 합니다. 이 때 Embedding 된 벡터의 성질에 따라서 Sparse Embeddding 과 Dense Embedding 으로 분류할 수 있습니다.
주의해야할 사항으로는, 둘 중 하나가 다른 것보다 무조건 ‘좋다’라기 보다는 각각이 강점을 가지는 분야가 다르다는 것이며 그로인해 상황에 맞추어 더 적합한 방법을 선택해야 할 필요가 있습니다.
이번 대회의 Inference 는 Test dataset의 question에 대해서 Retrieval을 통하여 유사한 Top-k 개의 passage를 가져오도록 한 뒤 해당 passage들을 question 뒤에 concat 하여 reader 모델로 정답을 예측하는 과정으로 이루어졌습니다. k를 늘릴 수록 Retrieval의 성능은 향상되었으나, reader 모델의 혼란이 가중된다는 문제가 있었기에 Retrieval의 성능을 개선할 필요가 있었습니다.
Sparse Embedding
다양한 Sparse Embedding 방법론 중 저희는 TF-IDF 와 BM25 를 집중적으로 사용하였습니다.
TF-IDF
TF-IDF는 여러 문서로 이루어진 문서군이 있으면, 어떤 단어가 특정 문서 내에서 얼마나 중요한 것인지를 나타내는 통계적 수치입니다. 이를 이용해 질문에 대해 정답이 있을 만한 문서를 찾아낼 수 있습니다. TF와 IDF의 곱으로 문서의 랭킹을 매기며 TF와 IDF가 의미하는 건 다음과 같습니다.
TF
- Term Frequency의 약자로 단어의 등장 빈도를 말합니다.
- 특정 단어가 문서 내에 얼마나 자주 등장하는지를 나타내고, 이 값이 높을수록 문서에서 중요하다고 가정 할 수 있습니다.
IDF
- Inverse Document Frequency의 약자로 단어가 제공하는 정보의 양을 나타냅니다.
- DF는 단어가 문서군내에 등장하는 빈도를 의미하며 IDF는 이것의 역수를 취한 후 로그를 취하여 얻습니다.
- the, a 같은 관사는 TF는 높아도, 거의 모든 문서에 등장하게 되므로 IDF의 값이 0에 가깝기 때문에 단어가 나타내는 정보 자체는 낮다고 할 수 있습니다.
- 자주 등장하지 않는 고유 명사 같은 경우 IDF가 커지기 때문에 단어 자체가 가지는 정보량은 많다고 불 수 있습니다.
TF 값과 IDF의 값을 곱해 주는 것으로 문서에 대한 Sparse Embedding을 진행 할 수 있습니다.
TF-IDF를 이용한 Retrieval은 다음과 같은 순서로 진행됩니다.
- 사용자가 입력한 query를 토큰화
- 기존에 단어 사전에 없는 토큰들은 제외
- query를 생각하고 이에 대한 TF-IDF 계산
- query의 TF-IDF 값과 문서군들의 TF-IDF 값을 곱하여 유사도 계산
- 가장 높은 점수의 문서를 선택
BM25
BM25 는 TF-IDF의 개념의 바탕으로 문서의 길이까지 고려하여 점수를 산정합니다.

BM25는 실제 검색엔진, 추천 시스템 등에서 아직까지도 많이 사용되는 알고리즘이며 TF-IDF 보다 Retrieval 성능이 뛰어났습니다. 하지만 Vectorize 를 하는 과정, 주어진 Passage 에 fitting 을 진행하는 과정, 그리고 Top-k passage 를 가져오도록 할 때 많은 시간이 소요된다는 문제가 있었습니다.
Elastic Search
Elastic Search는 확장성이 뛰어난 오픈소스 풀텍스트 검색 및 분석 엔진입니다. 방대한 양의 데이터를 신속하게, 거의 실시간으로 저장, 검색, 분석할 수 있도록 지원합니다. 일반적으로 복잡한 검색 기능 및 요구 사항이 있는 애플리케이션을 위한 기본 엔진/기술로 사용됩니다.
Elastic Search 는 검색엔진으로 뛰어난 속도로 방대한 양의 문서를 검색할 수 있습니다. 저희는 BM25 알고리즘과 Nori Tokenizer 기반의 Elastic Search 를 도입함으로써 단순 BM25 를 사용하는 것보다 약 2배 가량 빠른 시간에 Retrieval 을 진행할 수 있었습니다. 또한 동일한 BM25 를 사용하더라도 Tokenizer 에 따른 성능차이가 존재했습니다. 많은 Tokenizer 를 실험해보진 못했으나, 그 중에서 가장 성능이 좋았던 Nori Tokenizer 를 사용하게 되었습니다.
Validation Dataset 에 대해서 벤치마크를 측정했을 때, Top 20 개의 Retrieval 기준 Elastic Search 만으로도 93.75% 의 매우 높은 성능을 자랑했습니다. 하지만 유사한 문서를 많이 가져올수록 Reader 의 혼란은 가중될 것이므로 Retrieval 의 성능을 극대화 시켜서 Retrieval 로 가져온 문서를 최대한 적게 하자는 생각을 하게 되었습니다.
Dense Embedding
Sparse Embedding을 사용하면 검색하고자 하는 모든 문서를 이루고 있는 word에 대해 해당 문서가 가지고 있는 word를 표시해야 하므로 차원의 수가 매우 커지고 대부분의 특성이 0이 되는 문제가 있었습니다. 이러한 문제와 위의 생각을 바탕으로 Retrieval 의 성능을 향상시키기 위한 방법을 고려하던 중 Dense Embedding 을 도입해보기로 하였습니다.
Dense Embedding 은 문서들을 Embedding 할 때 Sparse Embedding보다는 낮은 차원, 고밀도 벡터로 Embedding 하는 것을 뜻합니다
Dense Embedding 에서의 각 차원은 특정 term에 대응되지 않고 대부분의 값이 0이 아닌 값들이기 때문에 각 Token 들의 Semantic 한 정보를 효율적으로 담아낼 수 있다고 생각하였습니다.
아이디어를 얻게 된 논문은 Dense Passage Retrieval for Open-Domain Question Answering 으로, 단순 Sparse Embedding 보다는 성능이 안좋았었지만 두 개의 BERT Encoder 를 사용하면서 성능이 비약적으로 발전하게 되었다고 합니다.
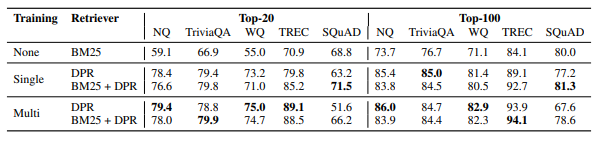
논문에서는 ODQA Task 에서 대부분 BM25 보다 DPR 의 성능이 좋다는 실험결과가 있었기 때문에 충분히 도입을 고려해볼만하다고 생각하게 되었습니다.
Dense Embedding의 생성, 학습
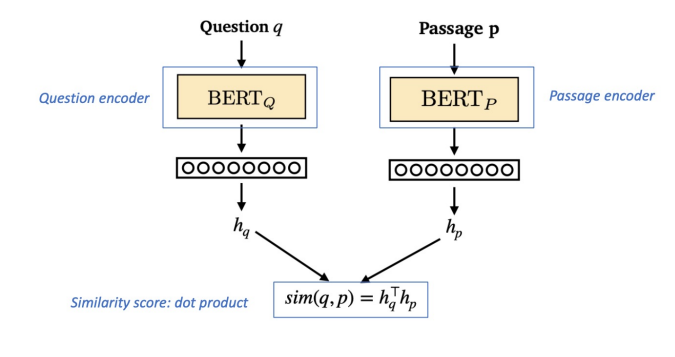
DPR(Dense Passage Retrieval) 에서는 두 개의 BERT Encoder 를 사용하여 Question 과 Passage 에 대한 Dense Embedding 을 생성한 후 내적을 통해 Similarity Score 를 구하는 방식으로 학습이 이루어집니다. 이때 각 배치에서 매칭되는 embedding vector들의 내적값은 정답으로 간주해 점수를 최대화 하고, 매칭되지 않는 vector들의 값들은 오답으로 간주해 점수를 최소화함으로 질문과 문서의 유사도 점수를 구하는 모델을 만들 수 있습니다.
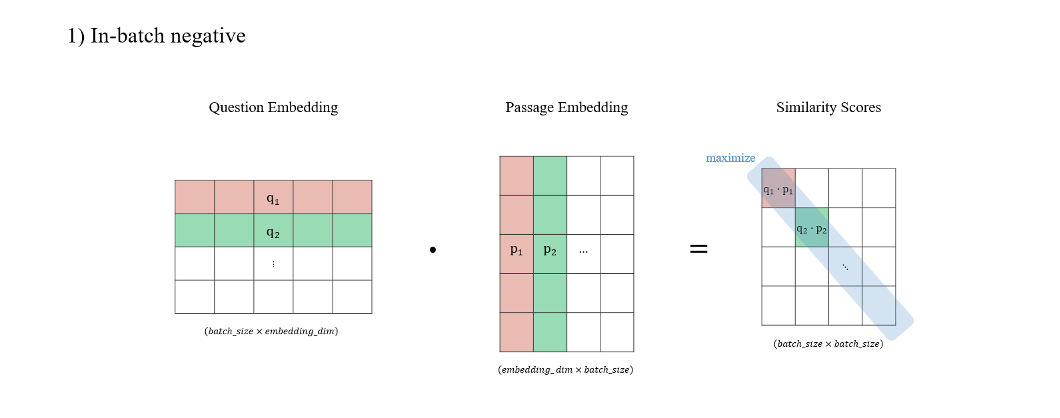
Finally, we explore in-batch negative training with additional ‘hard’ negative passages that have high BM25 scores given the question, but do not contain the answer string (the bottom block). These additional passages are used as negative passages for all questions in the same batch. We find that adding a single BM25 negative passage improves the result substantially while adding two does not help further.
참고한 논문에서는 이렇게 점수를 최대화 할때 오답들을 배치의 매칭되지 않는 값으로 하는 것에 추가로 question에 대한 정답이 passage에는 없지만 BM25 점수가 높은 문장들을 추가적으로 오답으로 간주하게 하여 (Hard negative passage) 학습시키는 방법론을 제시합니다.
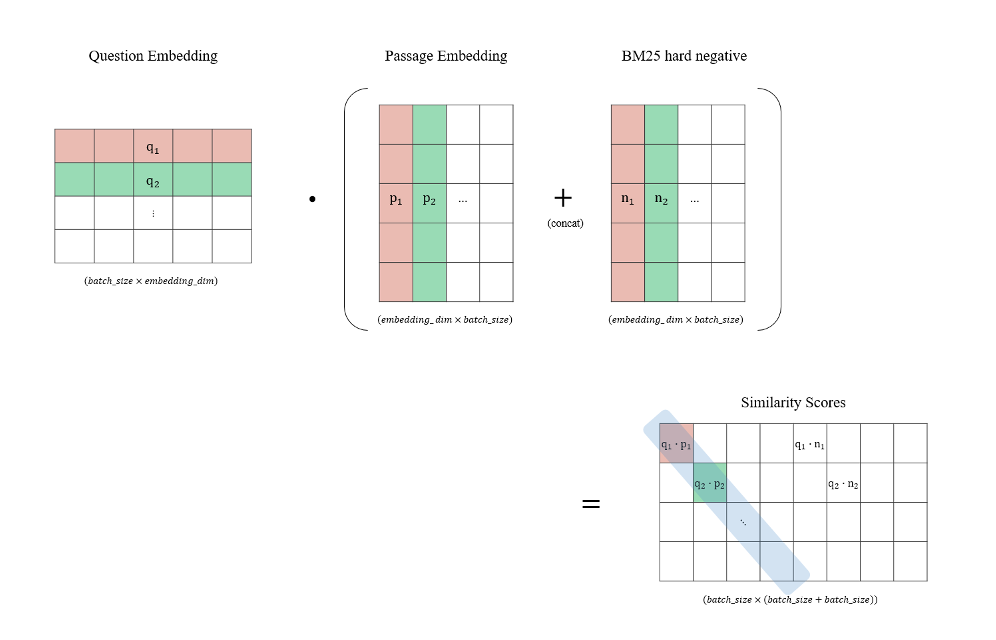
저희는 이러한 방법론을 도입하여 BM25 로 Negative Sampling 을 진행한 뒤 유사도 행렬에서 주대각선의 값들이 최대가 되는 방향으로 학습을 진행하였습니다.
하지만 막상 실험을 해보니 DPR의 성능은 만족스럽지 못했고, 오히려 TF-IDF보다도 점수가 낮았습니다. 이러한 원인으로 아래와 같은 이유를 예상해볼 수 있었습니다.
- 학습 데이터에는 질문에 주요 Term 들이 많이 포함되어 있었기 때문에 오히려 질문에 포함된 단어들의 의미를
추론하여 정답을 뽑는 것이 아니라 질문만 보고도 어느정도 답을 예측할 수 있었기 때문일 것이다. - 데이터셋을 제작한 Annotator 가 질문에 대한 답을 알고 있는 상태로 질문을 생성했기 때문에 어느정도의 bias 가 생겼을 것이다.
We conjecture that the lower performance on SQuAD is due to two reasons. First, the annotators wrote questions after seeing the passage. As a result, there is a high lexical overlap between passage and questions, which gives BM25 a clear advantage. Second, the data was collected from only 500+ Wikipedia articles and thus the distribution of training examples is extremely biased, as argued previously by Lee et al. (2019).
- 저희가 참고한 논문에서는 SQuAD 데이터셋이 이러한 문제점을 안고 있어서 DPR 보다 BM25 의 성능이 뛰어나다고 언급하고 있기 때문에 비슷한 이유를 예상해볼 수 있었습니다.
Bi-Encoder Embedding & Cross-Encoder Rerank
다음으로 시도해본 것은 Bi-Encoder Embedding 을 사용하여 관련 문서를 가져온 뒤 Cross-Encoder 로 Retrieval 을 Rerank 하는 방식입니다. 해당 문서 Retrieve & Re-Rank 에서 아이디어를 얻을 수 있었습니다.
Sentence BERT 는 Bi-Encoder 를 사용하여 Large-scale 의 Similarity Comparison, Clustering, Information Retrieval 로 활용할 수 있는 Sentence Embedding 방법론입니다.
기존의 BERT 로 유사한 두 문장을 찾기 위해서는 (n * (n - 1)) / 2 번의 연산을 수행해야 했기 때문에 굉장히 비효율적이며 연산량이 많았습니다. Sentence BERT 는 이러한 문제를 해결하고 Siamese 네트워크로 문장을 벡터화할 수 있는 방법을 제안했습니다. 따라서 STS(Semantic Textual Similarity) 데이터셋으로 사전학습된 Sentence BERT 를 사용하면 보다 빠르게 더욱 유사한 Embedding 을 추출할 수 있을 것으로 예상했습니다.
Bi-Encoder Embedding & Cross-Encoder Rerank 방식으로 Retrieval 을 수행하는 코드는 아래와 같습니다.
1 | |
Top 1 의 Retrieval 을 수행했을 때는 DPR 보다 높은 정확도를 기록하였지만, k 의 개수를 높일수록 DPR 보다 성능이 낮게 나왔는데, 그 이유로는 저희가 사용하던 학습데이터에 추가적인 fitting 을 진행하지 않았기 때문으로 예상됩니다. Bi-Encoder 를 학습시키기 위해서는 유사도를 기반으로 labeling 된 데이터가 필요했으며, sentence_transformer 라이브러리에 대한 추가적인 학습 등 fitting 을 진행하기엔 많은 비용이 필요했습니다.
만약 이 방법을 보다 빠른 시점에 시도하고 실험을 진행할 수 있었으면 Retrieval 의 성능을 보다 비약적으로 발전시킬 수 있었을 것이란 생각을 하게 되었습니다.
Hybrid (BM25 + DPR)
하지만 위와 같은 이유들에도 불구하고 저희는 DPR 의 배경과 장점, 가능성에 공감하여 어떻게든 DPR 을 활용해보려고 했으며, BM25 와 같은 Sparse Embedding 의 단점인 Semantic 한 단어들을 포착하는데 어려움이 있다는 것을 보완하기 위하여 DPR 과 Elastic Search 로 나온 Retrieval 결과를 혼합하여 사용하는 방식을 도입해보기로 하였습니다. 논문에서는 Multi Training (BM25 + DPR) 라는 키워드로 언급하고 있으나, 저희는 Hybrid Retrieval 라는 이름으로 명명하였습니다.
Hybrid Retrieval 은 BM25 Score 에 DPR 의 내적값인 sim(q, p) 를 더하여 문서를 Re-ranking 하는 방식입니다.
유령은 어느 행성에서 지구로 왔는가? 라는 질문에 대한 답을 포함하는 문서의 Title 은 더크 젠틀리의 성스러운 탐정사무소 입니다. 해당 질문에 대한 Elastic Search, DPR, Hybrid Retrieval 의 예시는 아래와 같습니다.
1 | |
1 | |
1 | |
Elastic Search 와 DPR 모두 질문에 대한 정답이 있는 문서를 찾지 못했으나, 이 둘의 점수를 선형결합한 Hybrid retrieval 은 정답이 포함된 문서를 1순위로 가져오는 것을 확인할 수 있었습니다.
Retrieval 성능평가
저희는 위에서 실험한 모든 Retrieval 의 성능평가를 진행했고, 그 결과는 아래와 같습니다. 모든 구간에서 Hybrid Retrieval 의 성능이 가장 높았으며, 저희의 예상대로 DPR 이 BM25 의 단점을 잘 보완해준다는 것을 확인할 수 있었습니다.
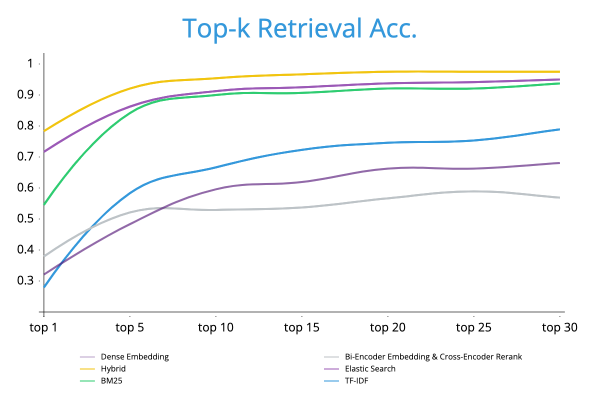
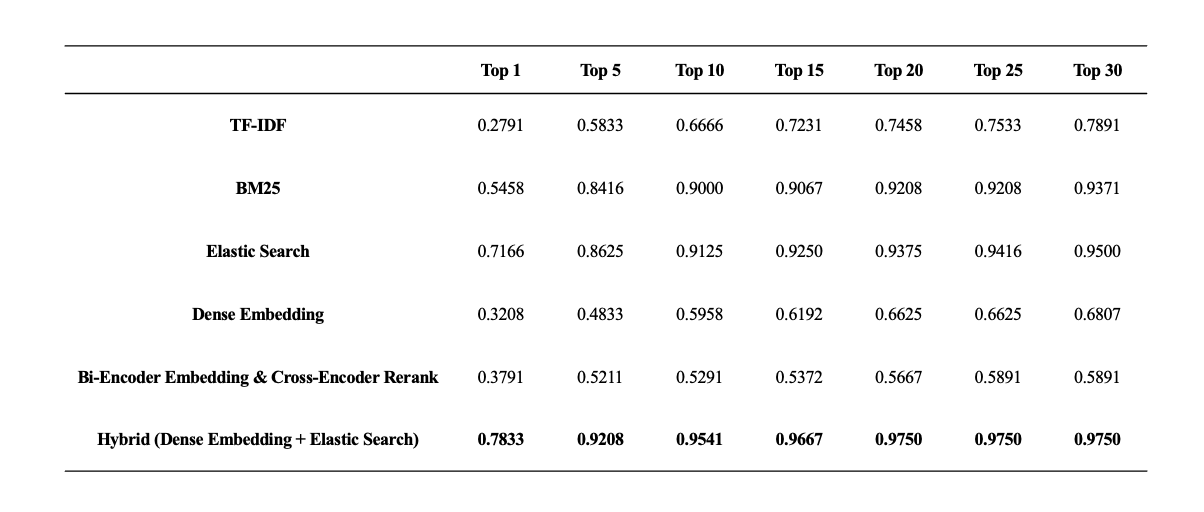
최종적으로 가장 성능이 좋았던 Hybrid Retrieval 을 선택하게 되었고, Top-k 로 가져오는 Passage 의 개수는 Reader 모델을 실험하고 Leaderboard 에 제출하면서 최적의 개수를 찾기로 결정하였습니다.
Reader
Reader는 주어진 질문에 대해 Retrieval이 가져온 문서를 읽고 정답을 찾아내는 모델입니다.
Reader의 경우 Extractive 와 Generative 방식이 존재하는데, Extractive Reader는 문서 내에서 모델이 정답일 것으로 예측하는 토큰의 시작과 마지막 인덱스의 확률(logit)을 구하고 이들의 합이 최대가 되는 문자열을 정답으로 예측합니다. 반면 Generative Reader는 문서를 읽고 정답일 것으로 예측되는 토큰을 생성하여 만들어낸 문자열을 정답으로 예측합니다.
학습데이터의 양이 매우 적었기 때문에 사전학습된 한국어 모델을 활용하고자 했으며, Extractive 방식에 집중하고자 했습니다. 영어의 경우 일반적으로 Generative Reader가 성능이 좋다고 알려져 있습니다. 왜냐하면 Extractive Reader의 경우 정답이 반드시 문서 내에 존재해야 한다는 단점이 있는 반면, Generative Reader는 문서 내에 정답이 존재하지 않아도 충분히 정답이 될 토큰을 생성해낼 수 있기 때문입니다. 하지만 Huggingface Hub에 공개되어 있는 사전학습된 한국어 생성 모델중에 중에 저작권 문제 없는 모델들은
hyunwoongko/kobart(seq2seq)google/mt-5계열 (seq2seq)kykim/gpt3-kor-small_based_on_gpt2(gpt2)
위의 세 가지 정도였고, Extractive Reader로 사용할 수 있는 Language Model들과는 다르게 모델의 크기가 적고 실제 Baseline 성능평가 당시 사전학습된 Extractive Reader로 Fine-tuning 하는 것보다 성능이 낮았기 때문에 Generative 방식은 사용하지 않았습니다.
저희는 Reader 의 성능 개선을 위한 모든 아이디어들에 대하여 실험을 진행하였고, 실험 결과들에 의해서만 좋은 방법들을 취사선택하였습니다.
Backbone
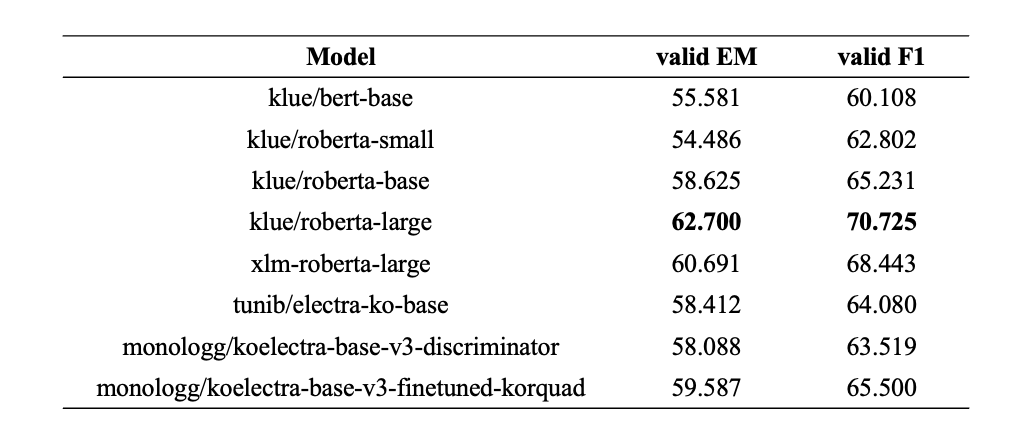
Extractive 방식으로 사용할 수 있는 여러 가지 사전학습 모델로 성능평가를 진행했고, 테스트 결과 validation EM 기준 가장 점수가 높았던 klue/roberta-large 모델을 backbone 으로 삼게 되었습니다.
Performance evaluation of backbone according to retrieval
사전학습된 Backbone 모델의 정확한 성능평가를 위하여 baseline 에 주어진 inference 코드로 evaluation 을 진행했습니다. 처음에 주어졌던 retrieval 방식은 TF-IDF 를 이용하여 질문에 대한 Top-k 개의 문서를 가져온 뒤 아래와 같이 불러온 문서를 모두 붙여서 정답의 시작과 마지막 인덱스를 예측하도록 이루어져 있었습니다. 질문에 Top-k 개의 문서를 붙인 뒤 Inference를 하기 위한 모델의 input 형식은 아래와 같습니다.
1 | |
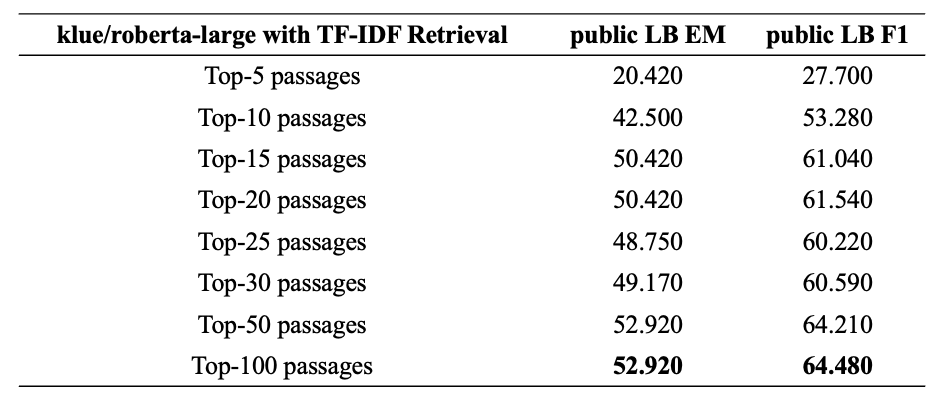
K의 개수를 늘릴 수록 public leaderboard 와 validation score 의 간극이 줄어드는 것을 확인하였고, 이러한 retrieval 방식에 착안하여 다음 실험을 계획할 수 있었습니다.
Concat Top-k Negative Samples
해당 방법의 아이디어를 얻은 논문은 Retrieval 과정에서 많이 참고한 Dense Passage Retrieval for Open-Domain Question Answering 입니다. 해당 논문에서는 Retrieval을 위한 Dense Embedding을 만들 때
Our best model uses gold passages from the same mini-batch and one BM25 negative passage.
BM25를 통해 가져온 negative sample을 추가하여 같이 학습시켰을 때가 가장 높은 퍼포먼스를 내는 모델이었다고 언급합니다. 이 실험에 착안하여 Reader 모델 학습 때 역시 negative sample을 추가하여 학습시키면 성능이 향상될 것이란 기대를 하게 되었습니다.
해당 실험을 통해 성능이 향상될 것이란 기대를 하게된 근거는 아래와 같습니다.
- 현재 Inference 는 Retrieval 로부터 질문과 유사한 Top-k 개의 passage를 불러온 뒤 concat 하고 그 안에서 Extractive Reader 가 정답을 찾게 하는 과정으로 이루어진다. Inference 과정처럼 Reader 모델 학습 때도 여러 passage를 concat 해놓고 정답을 찾게 하는식으로 최대한 비슷한 환경을 조성해 놓으면 예측 때 모델의 혼란이 줄어들 것이다.
- Retrieval 이 upgrade 되더라도 실험의 전제가 변하지 않을 것이고, 동일하게 학습시켜놓았던 모델로 더 좋은 결과를 얻을 수 있을 것이다.
- answer 키워드가 반복될 수 있는 positive sample 을 사용하면 오히려 모델의 혼란이 가중될 것이다.
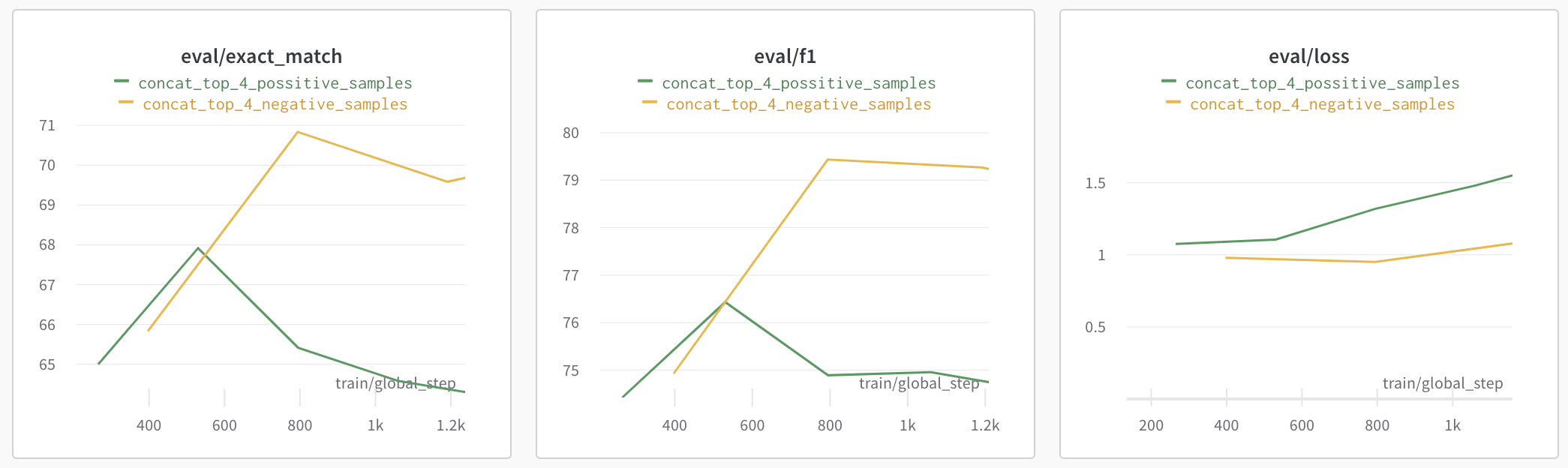
실험결과 예상과 같이 여러 passage를 concat 하였을 때 기존 validation score 보다 높은 점수를 기록하였고, possitive sample 보다는 negative sample 을 concat 하여 Reader 를 학습시켰을 때 훨씬 높은 점수를 기록할 수 있었습니다.
Negative sample 을 선택하는 방법에 따라서도 Reader 의 성능이 천차만별이었습니다. 특히 Retrieval과 Tokenizer 의 영향을 가장 많이 받을 것으로 예상했고, 두 가지에 집중하여 가장 좋은 성능을 내는 negative sample 을 뽑을 수 있도록 하였습니다.
사용할 수 있는 Retrieval 은 BM25, Elastic search, Hybrid retrieval 이 있었으며, Tokenizer 는 Elastic search 에 사용되는 Nori Tokenizer 와 BERT Tokenizer 가 있었습니다. 저희는 이 조합들을 사용하여 validation 을 측정해보았고 실험결과는 아래와 같습니다.
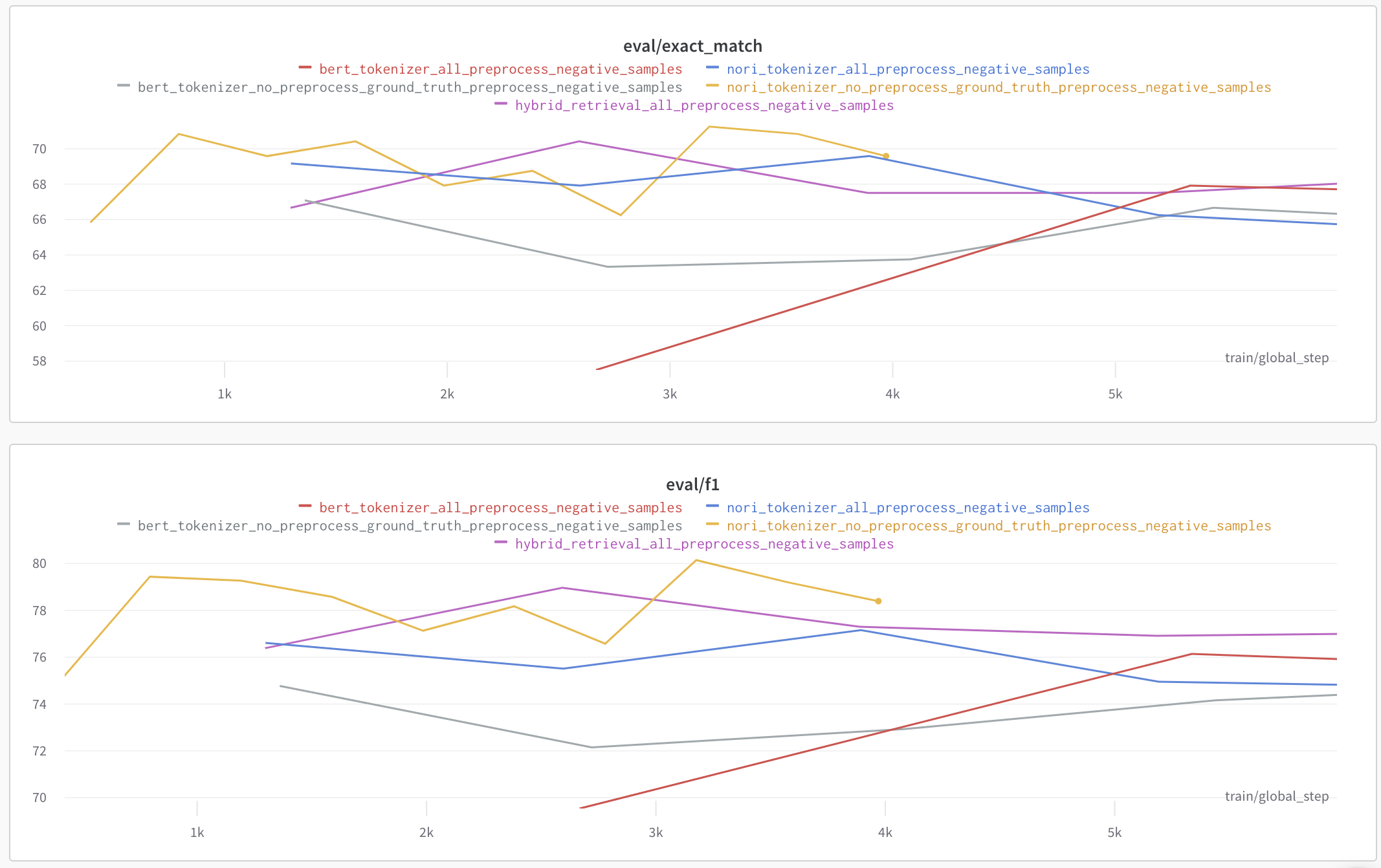
결국, 최종적으로 사용한 Negative Sampling 기준은 아래와 같습니다.
Elastic Search 와 Nori Tokenizer 를 사용하며, 정답을 포함하지 않는 상위 4개의 전처리된 passage
처음에는 Retrieval 성능이 올라갈수록 모델이 더 혼동하기 쉬운 Negative Sample 을 많이 포함시켜 Reader 의 성능이 오를 것으로 예상하였으나, 막상 실험을 해보니 Hybrid Retrieval 보다는 BM25 계열의 Sparse Embedding 을 활용하여 negative sampling 을 진행했을 때 결과가 더 좋았습니다.
이러한 원인을 Hybrid Retrieval 로 Negative Sampling 을 진행한 Dataset 에 중복되는 문서들이 더 많다 는 것으로 예상할 수 있었습니다.
기존 Train dataset 에는 약 500 건 정도의 ground truth passage 가 중복이었고, 저희가 사용하는 wiki 에는 중복되는 Passage 가 약 3,000 개, 같은 title 의 문서이지만 문단이 다른 경우가 약 29,000 개로 unique 한 wiki 문서는 총 31,755 개였습니다.
.png)
이 때 저희의 방식으로 Train dataset 에 대하여 Top-k (k=4) 개의 문서를 합쳤을 때 총 19,760 개의 wiki passage 를 보게 되는데, 위의 차트와 같이 Hybrid Retrieval 로 Negative Sampling 을 진행하였을 때 중복된 문서가 약 1,400 개 정도 더 포함되어 있었습니다. 또한 Semantic 한 정보까지 포함하여 고려하는 Hybrid Retrieval 을 사용하게 되면 중복된 Ground Truth 에 포함되는 Negative Sample 들이 대체로 일치했습니다. 따라서 이미 너무나도 쉽게 Over-fitting 이 발생하는 상황에서 중복되는 Passage 를 많이 포함시키며 오히려 Negative Sample 로서 기대했던 역할을 제대로 수행하지 못하게 되었다고 생각했습니다.
hyperparameter tuning
위의 실험들을 바탕으로 Elastic Search 로부터 Top-k 개의 negative sample 을 포함하여 데이터셋을 재구축하였고, 그 중 가장 성능이 높았던 k=4 를 기준으로 hyperparameter tuning 을 진행했습니다. Optuna 라이브러리와 Huggingface Trainer 에 존재하는 hyperparameter_search 함수를 사용하였고, batch size, learning rate, seed, gradient accumulation step, weight decay 다섯 개에 대하여 validation EM score 를 maximize 할 수 있도록 search 를 진행했습니다.
1 | |
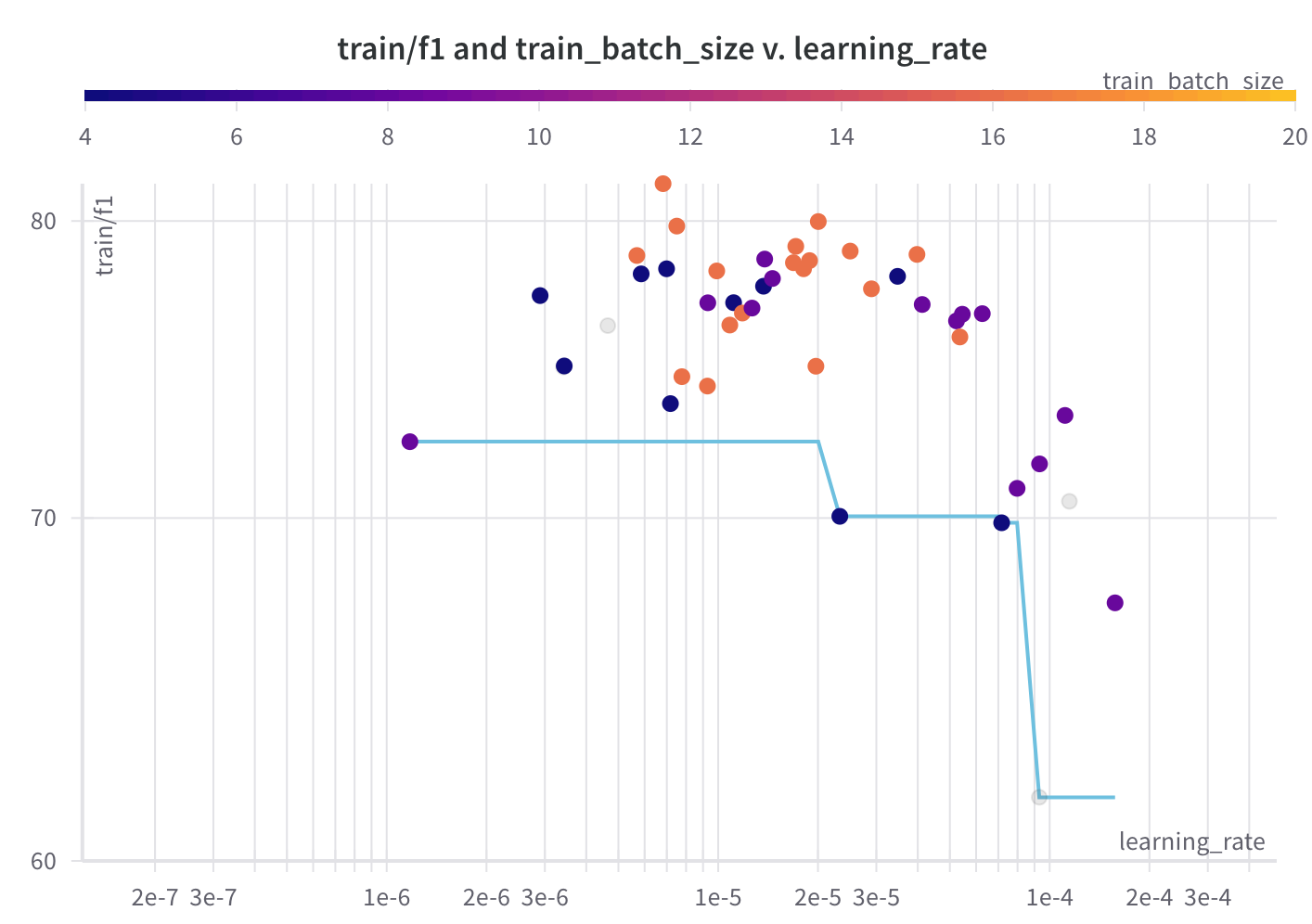
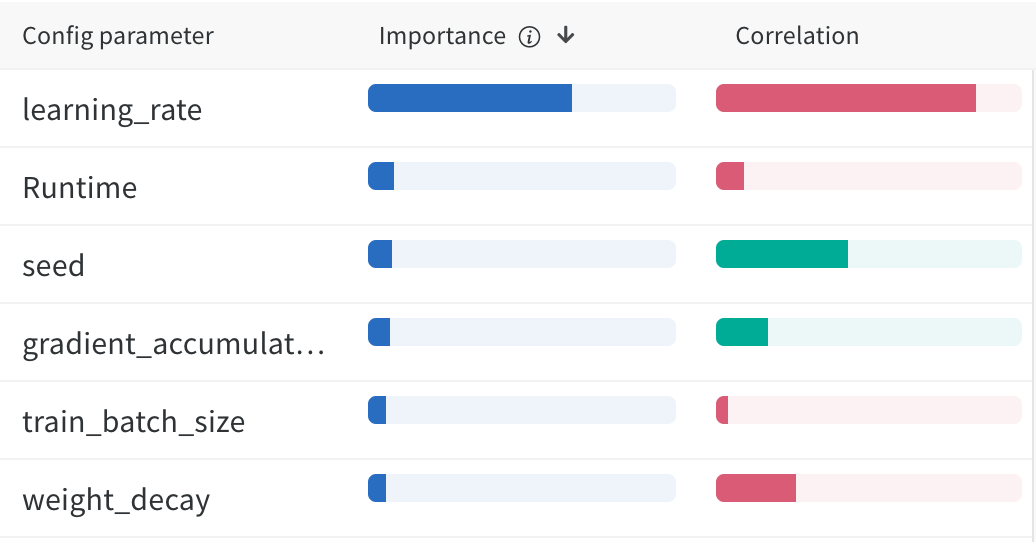
Hyperparameter Search 를 진행하면서 Validation Score 가 굉장히 Sensitive 하게 변동되는 경향이 있었고, 그 때문에 결과가 좋지 않은 Trial 에 대하여 Pruning 이 올바로 동작하지 않는 이슈가 있었습니다. 따라서 모델의 성능이 어떠한 Parameter 에 많은 영향을 받고 어떤 조합일 때 점수가 높게 분포되는지를 확인해보았습니다. 결과적으로 learning rate 의 영향을 상당히 많이 받으며, batch size 가 클 때 학습이 가장 잘 이루어진다는 것을 알 수 있었습니다.
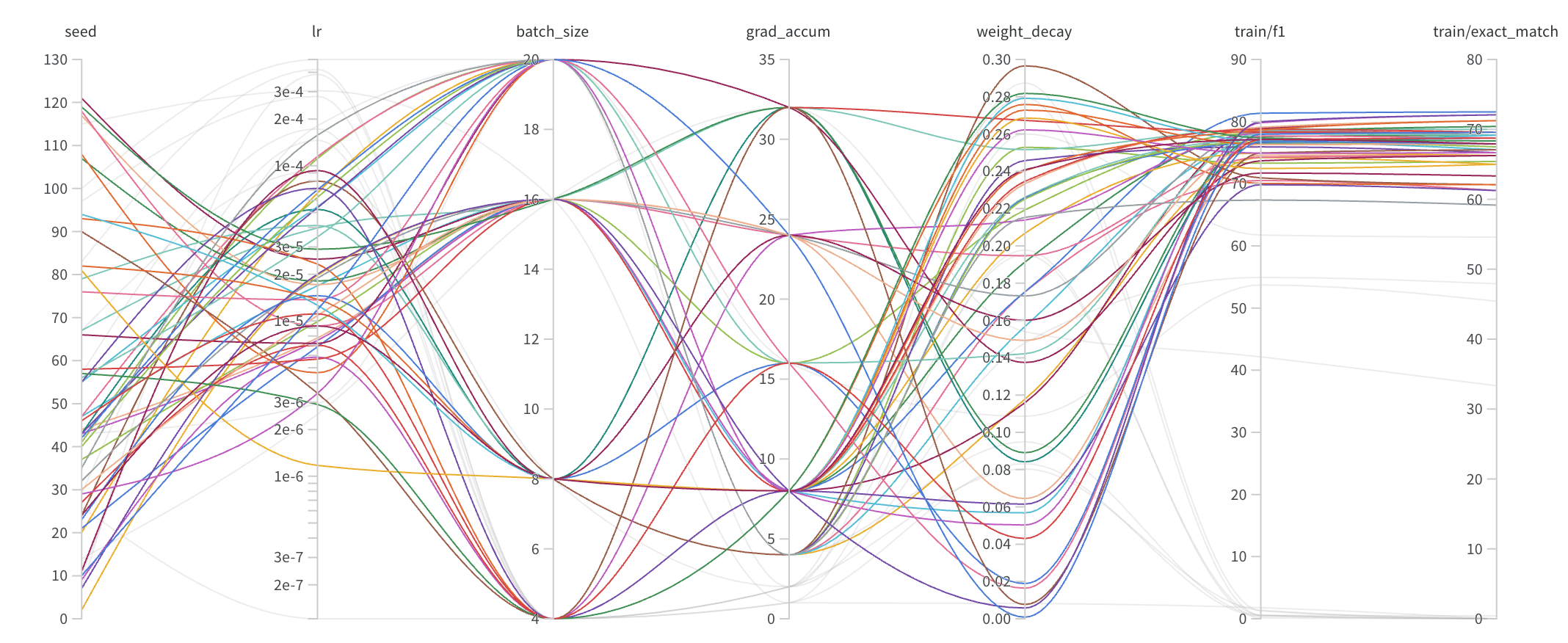
그렇게 약 60번의 trial 을 시도했고, Learning rate 와 batch size 에 주목하며 Search 를 진행하는 Hyperparameter 범위를 좁혀가며 실험을 진행했습니다. Search 가 끝난 이후에는 W&B의 sweep 기능을 이용하여 가장 좋은 조합을 찾을 수 있었습니다.
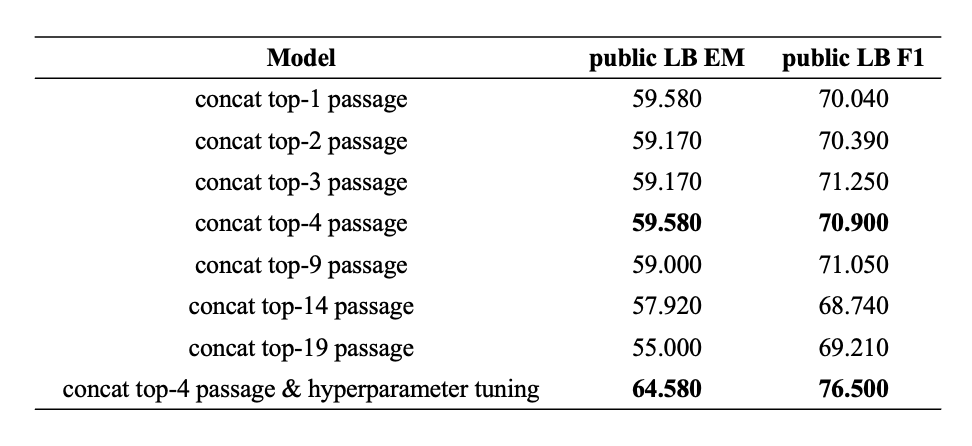
그렇게 public leaderboard 기준 5 이상의 score 향상을 얻을 수 있었습니다.
Custom Heads
실험을 이어가면서 Test dataset 에 대해 Inference 를 하고 나온 결과를 살펴보던 중 아래의 예시들을 통해 의문을 가지게 되었습니다.
- 예측한 정답에 형용사, 조사 등이 포함되어 있는 경우 -
대통령인 빌헬름 미클라스,<자유>지에 - 예측한 정답의 substring 이 반복되는 경우 -
주노해변 주노해변 - 예측한 정답이 문장인 경우 -
남자아이 빈을 데려다 양자로 삼는다는 것에서..
Extractive 방식에 따라 문서 내에 존재하는 토큰의 위치를 찾게 되는데, 위의 예시처럼 형용사 를 포함해야 할 것인지, 반복 되는 키워드의 경우 어떻게 잘라내야 할 것인지, 문장 이 정답이라면 문장 전체를 정답으로 할 지, 아니면 명사구 가 될 수 있도록 end position 을 이동시켜야 할 지 등에 대한 고민을 하게 되었습니다. 그리고 이러한 문제가 발생한 원인은 모델이 ‘일관적이지 않게’ 정답을 추출해내고 있기 때문일 것으로 예상하고 사용하고 있던 huggingface 의 QuestionAnswering 소스 코드를 살펴보았습니다.

Huggingface 의 Extractive Reader 방식으로 사용되는 QuestionAnswering 모델의 head 는 backbone 의 sequence output shape 인 hidden_size 를 2(start_logit, end_logit) 로 축소한 Linear layer 가 사용됩니다. 저희가 backbone 으로 사용한 klue/roberta-large 의 경우 hidden_size 가 1,024 로 매우 컸는데, 실험을 이어가다 보니 이렇게 큰 사이즈의 벡터를 바로 두 개의 logit 으로 축소한다는 것에서 위의 예시와 같은 문제점들이 생겨날 수 있을 것으로 판단하게 되었습니다. 또한 다양한 head 를 사용하고 튜닝함으로써 모델이 보다 일관적으로 정답을 예측하고, 이러한 문제를 해결할 수 있을 것으로 기대하게 되었습니다. 마지막으로 최종 제출 전략인 Ensemble 을 고려하였을 때 head 에 다양성을 준 모델의 퍼포먼스가 낮아도 Ensemble 의 좋은 재료가 될 수 있을 것이란 기대로, 최대한 다양한 head 를 실험해보기로 하였습니다.
Head 에 custom layer 를 추가하기 위해 아래 논문과 블로그에서 아이디어를 얻게 되었습니다.
저희가 실험에 사용했던 Custom Layer 와 전체적인 Architecture 는 아래와 같습니다.
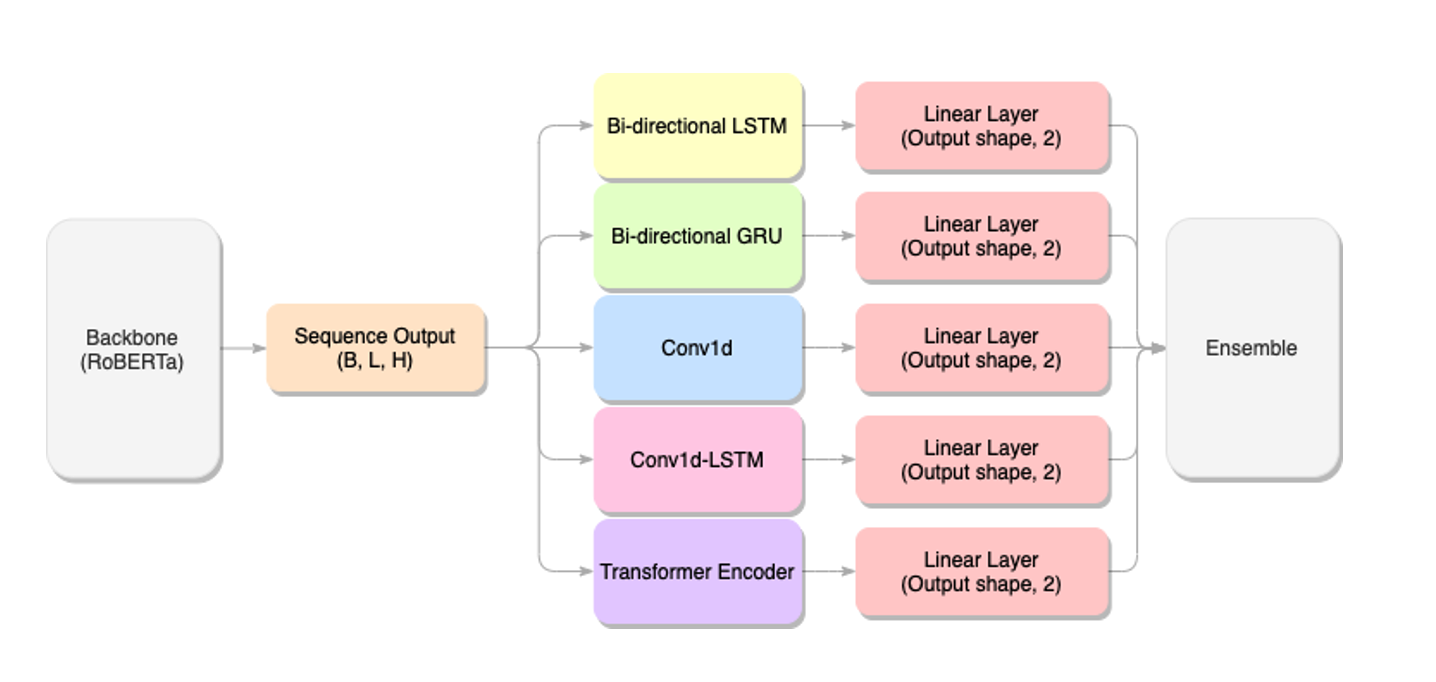
RNN Family 를 사용한 head 의 모델에서는 정답이 포함된 Sequence 에 조금 더 집중할 수 있기를 기대했고, CNN 은 정답과 조금 더 유사한 feature 들, Transformer Encoder 에서는 사전학습된 Backbone 의 representation 보다 주어진 학습 데이터에 집중하여 보다 성능을 개선할 수 있기를 기대했습니다.
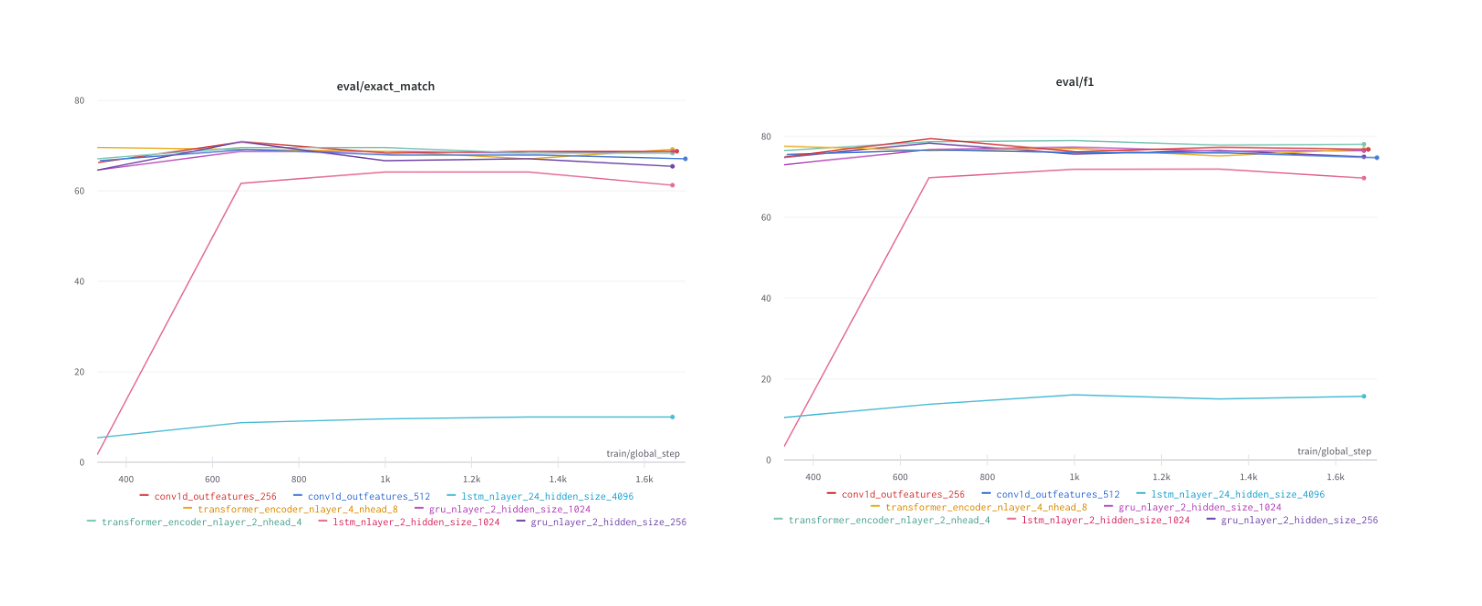
막상 실험을 진행하니, 현재 backbone 도 과적합이 쉽게 일어나는 sensitive 한 상황이었기 때문에 head 에서 복잡도를 키우게 되니 validation score 는 backbone 보다 하락하였습니다. 특히 Conv1d layer 에서는 out_feature 가 작을수록, RNN Family 에서는 hidden_size 가 클수록 좋은 성능을 보였으며 전체적으로 custom layer 의 개수를 늘릴 수록 학습이 제대로 진행되지 않았습니다.
Custom head 를 부착한 모델들로 inference 를 진행한 후 나온 nbest_predictions 를 정성적으로 살펴보았을 때 각각의 head 들의 특징을 대략적으로나마 알 수 있었는데
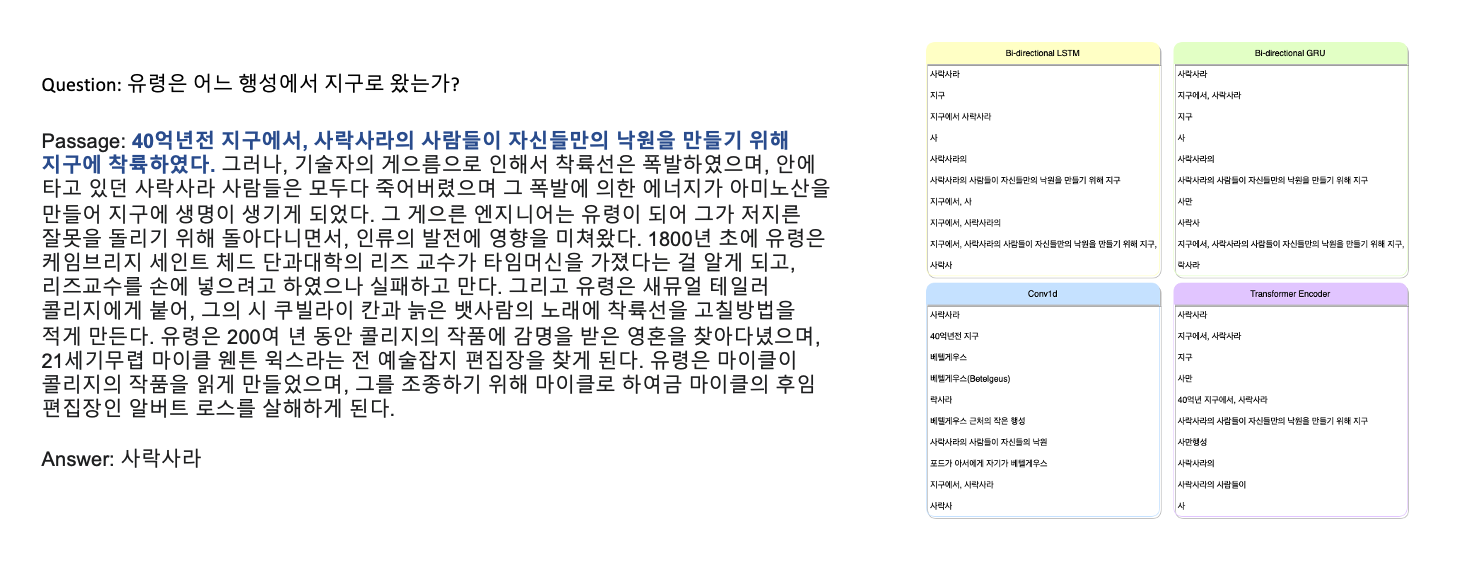
위의 예시에서 Conv1d 는 정답인 사락사라 와 비슷한 의미를 가진 ‘행성’, ‘지구’, ‘베텔게우스’ 등의 단어에 집중하는 모습을 보였고, Bi-LSTM과 Bi-GRU 는 정답인 사락사라 가 포함되어 있는 문장인 40억년전 지구에서, 사락사라의 사람들이 자신들만의 낙원을 만들기 위해 지구에 착륙하였다. 라는 시퀀스에 집중하였으며, Transformer Encoder 의 경우 Conv1d 와 RNN Family 의 특성을 모두 가지고 있는 듯한 경향을 보였습니다.
다만 각각의 모델들은 backbone 보다 public leaderboard score 가 비슷하거나 조금 더 낮은 점수를 기록하였습니다. 하지만 점수가 비슷함에도 예측한 정답들이 매우 달랐기 때문에 Ensemble 의 좋은 재료로 활용할 수 있을 것으로 예상할 수 있었습니다.
Data Augmentation
다음으로 시도한 것은 Data Augmentation 입니다. 학습 데이터가 너무 적었기 때문에 더욱 robust 한 모델을 만들기 위해서는 여러 방면으로 데이터를 증강한 뒤 다양한 데이터셋을 만들 필요가 있다고 생각했습니다. 크게 AEDA, Shuffling, Question Generation 세 가지 방법으로 Augmentation 을 진행하였으며, 해당 방법들로 약 10배 이상의 데이터를 만들 수 있었습니다.
AEDA
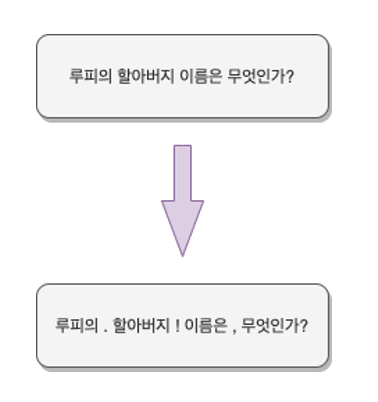
AEDA(An Easier Data Augmentation Technique for Text Classification) 는 Original Text 의 random 한 위치에 punctuation 을 삽입하는 Augmentation 방법입니다.
해당 논문에서는 Text Classification Task 에서 큰 성능 향상을 보았는데, 각각의 Token 사이에 노이즈를 추가함으로써 모델의 과적합을 방지하고 서로 붙어있는 Token 간의 의존성을 낮추어 일반화 성능이 좋은 모델을 만들어 낼 수 있지 않았을까 라는 생각을 하게 되었습니다.
이 생각을 바탕으로 학습데이터에 존재하는 질문들에다가 AEDA Augmentation 을 사용하면 짧은 Sequence 라고 하더라도 질문의 의도나 Representation 을 잘 파악할 수 있을 것이란 예상을 하게 되었습니다. 저희는 하나의 Question 에 대하여 1개, 2개, 4개, 8개의 augmentation sentence 를 생성하였습니다. 질문의 마지막에는 항상 ? 가 포함되어 있었기 때문에 마지막 인덱스를 제외한 text 에 [".", ",", "!", ";", ":"] 의 punctuation 들을 삽입했습니다. 빠른 작업속도를 위해 Mecab Tokenizer 를 사용하였고, 삽입하는 확률을 0.2 로 설정함으로써 punctuation 이 너무 자주 삽입되는 것을 방지했습니다.
하지만 Question + [SEP] + Ground Truth Passage + ' ' + Negative Samples 로 이루어지는 input 형태에서 Question 에만 변형을 주는 것은 좋은 성능으로 이어지지 않았습니다. 그 이유를 예상해보았을 때 Question 에 대한 학습에는 도움이 되었을 지 몰라도, 아래 두 가지를 떠올려볼 수 있었습니다.
- AEDA 를 수행한 sentence 가 많을수록 SEP Token 을 기준으로 합치는 Passage 들이 매우 많았기 때문에 실제 정답을 찾아내는 수행 능력만큼은 큰 차이가 없었을 것이다.
- 오히려 겹치는 Passage 에 대해서 보다 쉽게 overfitting 이 발생했기 때문에 inference 에서 기존보다 예측 결과가 나빴을 것이다.
따라서 AEDA 를 제외한 다른 Augmentation 방법에 집중하게 되었습니다.
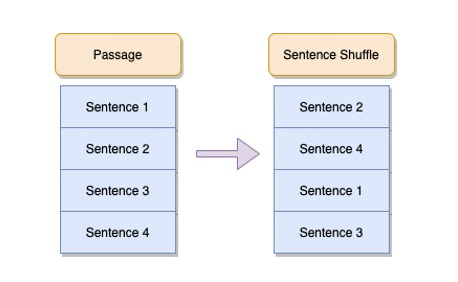
Sentence Shuffle
다음으로 시도한 Augmentation 은 Sentence 를 뒤섞는 방법입니다.

위의 예시를 다시 보면, 유령은 어느 행성에서 지구로 왔는가? 에 대한 정답은 사락사라 입니다. 이 때 정답이 포함된 문장은 Passage 의 가장 첫 부분에 나타나고 있습니다. 또한 이 질문의 경우 앞, 뒷문장 또는 문서의 맥락과 상관 없이 정답이 포함된 문장만 보더라도 정답을 예측할 수 있습니다. 이렇게 여러 문장과의 관계를 살피지 않고 한 문장만 보고 정답을 맞출 수 있는 쉬운 질문의 경우 다른 문장은 학습에 오히려 방해요소로 작용할 것이란 생각을 하게 되었습니다. 그 생각을 바탕으로 문장들을 뒤섞는 아이디어를 떠올리게 되었고 Data-Augmentation-NLP 해당 블로그를 참조하여 성능 향상 가능성을 보게 되었습니다.
1 | |
kss 라이브러리의 split_sentences 함수를 사용하여 passage 를 문장단위로 분리한 이후 random 으로 shuffle 을 진행하였습니다. 이 때 정답의 시작 인덱스가 변경되기 때문에, 분리한 문장 배열에서 원래 정답이 속해있던 문장의 index 를 hash_table 에 저장한 뒤 변경된 문장의 위치에서 올바른 정답을 찾아갈 수 있는 처리를 해주었습니다.

결과는 위의 사진과 같습니다. 문장의 위치를 섞어줌으로써 Backbone 에게 어려운 Sample 을 더 많이 보여주어 성능 향상을 기대해볼 수 있었습니다.
Passage Shuffle
기존에는 Ground Truth 에다가 Negative Sample 4개를 이어붙여서 학습을 진행했었는데 sentence shuffle 을 진행하면서 이어붙이는 passage 들도 뒤섞는 것에 대한 아이디어를 떠올리게 되었습니다. 왜냐하면 Ground Truth 가 항상 맨 앞에 등장하기 때문에 Reader 모델이 Passage 들의 앞부분에만 집중할 수 있다고 생각했기 때문입니다. 또한 inference phase 에서 Retrieval 의 score 대로 passage 를 이어붙이게 되는데, 이 때 정답을 찾을 수 있는 passage 가 맨 앞에 오지 않는다면, Reader 의 성능이 급격히 떨어질 수도 있을 것이란 생각을 하게 되었습니다.
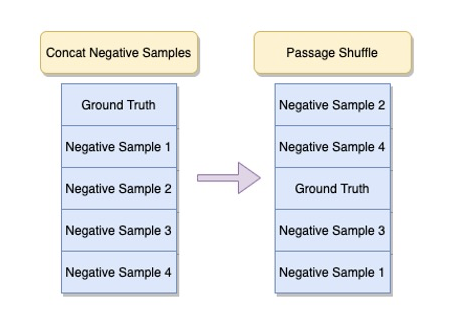
이러한 아이디어에 착안하여 위와 같이 Ground Truth 와 Negative Sample 의 순서를 random 하게 섞어줌으로써 Reader 의 성능 향상을 기대해볼 수 있었습니다.
Sentence Shuffle + Passage Shuffle
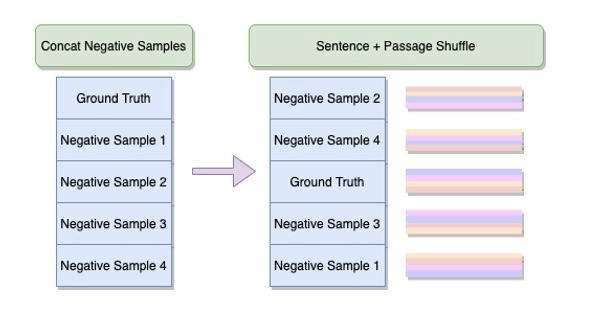
또한 앞의 두 아이디어와 비슷한 기대를 하며 Passage 들을 섞고 난 뒤 각각의 Passage 의 문장들까지 섞어놓은 학습데이터까지 구축하게 되었습니다. 이렇게 위의 세 가지 방식을 사용하여 처음보다 3배의 데이터를 추가로 확보할 수 있었습니다.
Question Generation
다음으로 시도한 Augmentation 은 Question Generation 입니다. 외부데이터셋 사용이 제한된 상태에서 사용할 수 있는 Augmentation 중 가장 기대를 많이했던 방법입니다. Conditional BERT Contextual Augmentation 논문을 보고 생성모델을 사용한 augmentation 기법에 아이디어를 얻게 되었고, 아래의 문서와 레포지토리를 참고하여 간단하게 Question Generation을 수행할 수 있었습니다.
질문을 생성하기 위해서는 Target 이 되는 Answer 가 필요했기 때문에 NER 을 활용하여 Entity 인 것들을 Target 으로하는 질문 생성과, Wiki 문서의 제목이 문서 본문에 포함되면, 제목을 Target 으로 하는 질문을 생성하는 두 가지 접근법을 생각해 냈습니다. 그리고 사전학습된 생성모델인 SKT-AI 의 KoGPT-2 와 Kakaobrain 의 KoBART 를 사용하여 새로운 질문을 생성해냈고, 학습 데이터와 유사한 형태의 데이터를 만들어낼 수 있었습니다.
NER + Question Generation
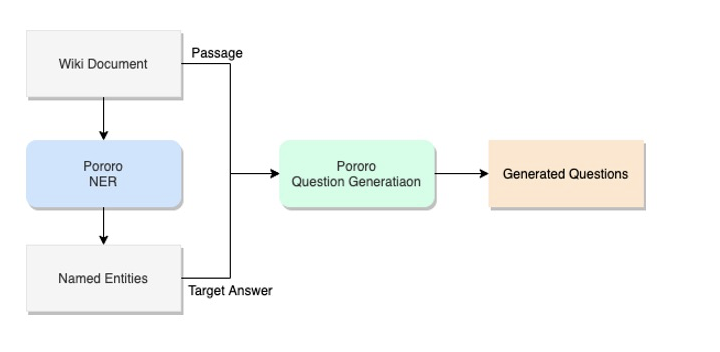
Pororo 의 NER 은 Entity 가 없으면
'O'를 반환합니다. 따라서 ‘O’ 가 부착되지 않은 Entity 를 정답으로 하는 질문을 생성해냈고, 약 14만 건의 데이터를 확보할 수 있었습니다. 다만 질문의 퀄리티가 상당히 좋지 않았기 때문에 filtering 을 거칠 필요가 있었습니다. 정성적으로 살펴본 결과 entity 의 길이가 짧은 것들 대부분에 의존명사가 포함되어 있었고, 질문이 이러한 entity 를 제대로 표현할 수 없겠다는 생각이 들었습니다.
학습 데이터셋의 정답 길이의 평균이 6 이상이었기 때문에 길이가 6보다 적은 entity 를 제거하였고, 약 2만 3천 개 정도의 질문이 남게 되었습니다. 또한 다른 target 에 대하여 동일한 질문이 곳곳에 포함되어 있었고, target 과 전혀 상관없는 질문이 생성되기도 하였습니다. 그래서 저희는 Pororo Semantic Textual Similarity 를 사용하여 질문과 답변의 유사도가 0.5 이상인 것들만 추려서 최종적으로 약 2천 개의 데이터를 확보하게 되었습니다.Wiki Title question generation
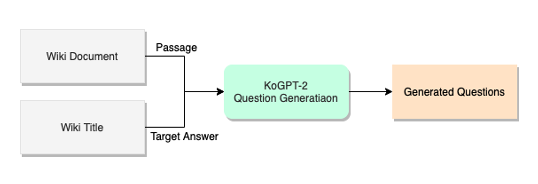
Named Entity 를 Target 으로 하여 생성해낸 질문들을 필터링하니 데이터가 별로 남지 않아서 다른 방법을 고안하게 되었습니다. Wiki의 title 을 Target 으로 질문을 생성해내면 문서를 대표하는 정답으로 질좋은 질문들을 생성해낼 수 있다고 판단했기 때문입니다. 이 때 주어진 Wiki 에서 중복을 제거하고, Title 이 겹치는 문서들도 제거한 31,726 개의 Wiki 문서에서 Title 이 문서 내에 포함되어 있는 문서의 개수는 약 17,000 개였습니다. 저희는 KoGPT-2 를 사용하여 17,000 여개의 정답을 Target 으로 하는 질문들을 생성했습니다.
그렇게 총 약 3만 개의 질의응답 데이터셋을 구축할 수 있었고, 이렇게 구축한 데이터셋들을 서로 다른 조합으로 하여 학습을 이어갔습니다. 하지만, Augmentation 한 데이터셋으로 학습하여도 기존의 리더보드 점수를 따라잡을 수 없었습니다.
Pororo 는 기본적으로 batchify 를 지원하지 않기 때문에 빠른 속도로 augmentation 을 진행할 수 없었습니다. 단순히 컴퓨터를 켜놓고 대기할 수 밖에 없었는데, 다음에는 batchify 방식을 구현하여 보다 빠른 작업을 진행해야 겠다는 생각을 하게 되었습니다.
Curriculum learning
Augmentation 을 진행했는데 성능 개선을 못 본 것에 대하여 아래와 같은 이유들을 생각해볼 수 있었습니다.
- 생성해낸 질문의 퀄리티가 생각보다 좋지 않아서 오히려 모델의 학습을 방해했다.
- 증강한 질의응답의 난이도가 너무 어렵다.
정성적인 평가를 진행했을 때 생성해낸 질문들 중에 이상하거나 중복된 질문들을 찾지 못했습니다. 또한 Sentence 와 Passage 를 모두 shuffle 한 학습데이터의 경우 Validation EM Score 가 40점을 넘기지 못했습니다. 때문에 두 번째 이유에 집중하여 모델의 학습 방식을 개선해보기로 하였습니다. 그 중에서도 Curriculum Learning - 대학원생이 쉽게 설명해보기 블로그를 참고하게 되었고 쉬운 샘플부터 점점 난이도를 높여가며 학습시키는 것이 일반화와 더 빠른 수렴에 도움이 된다는 것을 알게 되었습니다.
따라서 Level 1, 2, 3 세 단계를 두고 Augmented Dataset, Passage Shuffled Dataset, Sentence and Passage Shuffled Dataset 난이도별로 학습을 시켜보게 되었습니다.
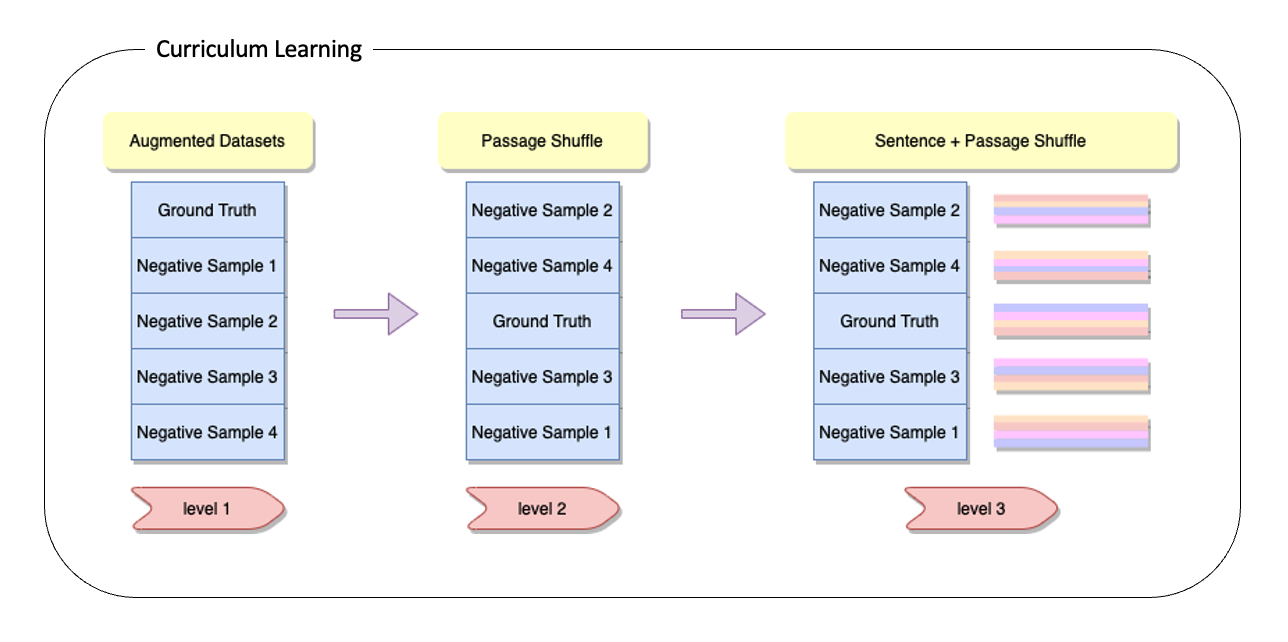
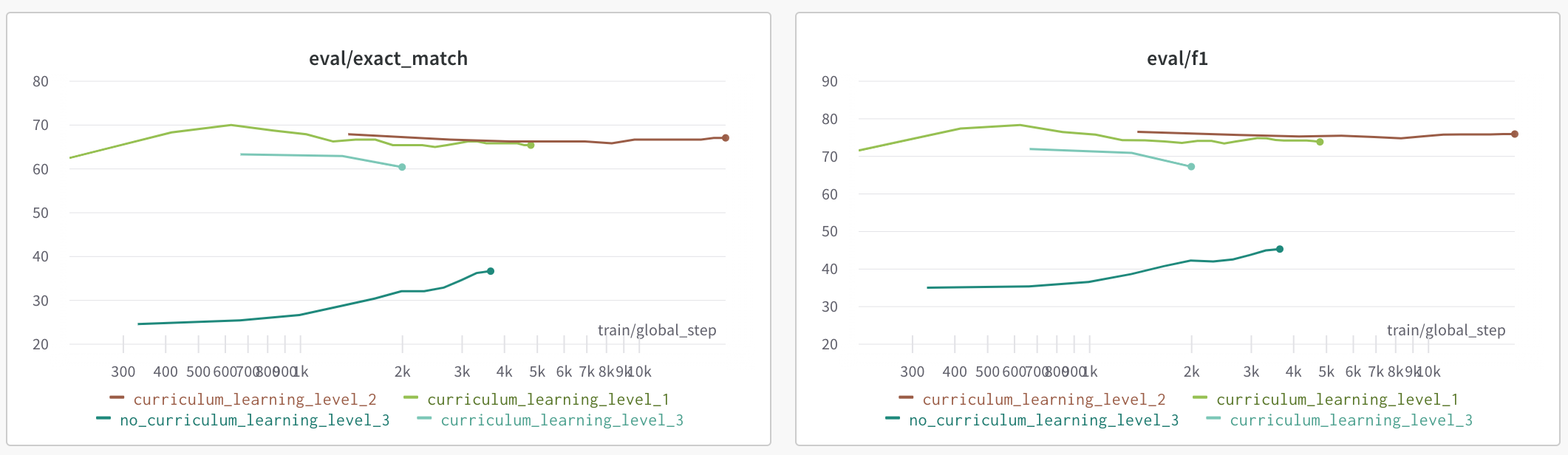
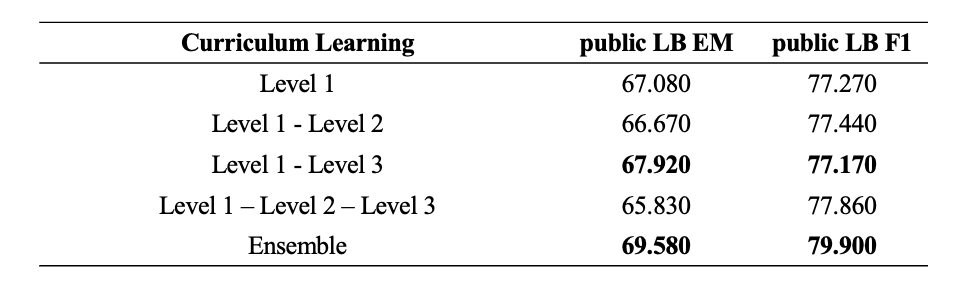
기존 가장 높은 점수를 기록했던 모델보다 약 3점의 스코어 향상이 있었고, Curriculum Learning 을 통해 얻은 결과들을 Ensemble 했을 때는 약 5점의 스코어 향상을 기록할 수 있었습니다.
Combine Models
이 외에도 여러 모델을 결합한 형태로 실험을 이어갔습니다. Combining numerical and text features in deep neural networks 해당 글에서 아이디어를 얻었으며, Single model 보다는 여러 모델의 hidden state 를 concat 하여 end-to-end 로 학습시킬 때 더 좋은 퍼포먼스를 기대할 수 있지 않을까라는 생각 때문이었습니다.
BERT 계열의 비슷한 모델을 Combine 하는 것은 단순 Layer 를 두 배로 늘리는 것 정도의 효과밖에는 기대하지 않았기 때문에, 최대한 Model 의 Architecture 가 다른 모델들을 가지고 실험을 해보고자 했습니다.
- Roberta-Electra
- Roberta-Bigbird
최종적으로는 위의 두 가지 조합을 사용하게 되었습니다. 위의 조합을 선택한 이유는 아래와 같습니다.
- Electra 의 경우 Generator 는 BERT 의 MLM 구조와 동일하지만, Discriminator 에 의해 RoBERTa 와는 다른 Representation 을 기대할 수 있을 것이다.
- Bigbird 의 경우 Block sparse attention 을 이용하여 Roberta 보다 긴 sequence 에 강력할 것이다.
하지만, 단순히 hidden state 를 concat 한 뒤 정답의 position 을 추출하는 방식만으로는 backbone 의 성능을 따라갈 수 없었습니다. 서로의 Representation 들이 다르기 때문에 이미 어느정도의 Features 를 학습한 사전학습 모델을 결합하는 것으로는 좋은 효과를 도출해낼 수 없었던 것으로 예상됩니다. Scratch 부터 학습을 진행했으면 더 좋은 성능을 기대해볼 수 있었을 것으로 기대합니다.
Pytorch Versionup
다른 팀원이 가장 좋은 성능의 모델을 재현하던 중 다른 pytorch 버전으로 학습시켰을 때 결과가 다르다는 소식을 전해들었고, Seed 를 고정했음에도 다른 결과가 나온 것이 이상하여 원인을 찾던 중 아래와 같은 이슈를 발견할 수 있었습니다.
RNG(Random Number Generator) 혹은 PyTorch 버전에 따른 Random Number 에 따라서 결과 재현이 안될 수도 있고, 모델의 수렴속도가 달라질 수 있다.
또한 PyTorch 혹은 Huggingface transformers 와 같은 라이브러리의 버전에 따라서도 float dividing 이나 연산의 처리가 달라질 수 있기 때문에 버저닝에 따른 결과가 다를 수 있다는 것을 알게 되었습니다. 저희는 Pytorch 를 가장 최신버전인 1.10.0 으로 업그레이드하여 조금의 성능 향상을 이끌 수 있었습니다.

결과적으로 위의 모든 시도들을 종합했을 때 Public Leaderboard 에서 단일모델 69.580 이라는 점수를 달성할 수 있었습니다.
KFold Cross Validation
저희는 Private Leaderboard 가 공개되었을 때 shake up 이 발생하는 것에 경각심을 가지고 있었습니다. 따라서 모델의 일반화 성능을 향상시키기 위해 KFold 교차검증 방식을 도입하기로 했습니다.
sklearn 의 KFold 를 이용하여 dataset 을 분리하였고, 정답이 되는 토큰의 위치를 찾아내는 Extractive Reader 방식이었기 때문에 start 와 end logit 들의 평균을 구하고 그 평균값으로 후처리를 진행하도록 하였습니다.
1 | |
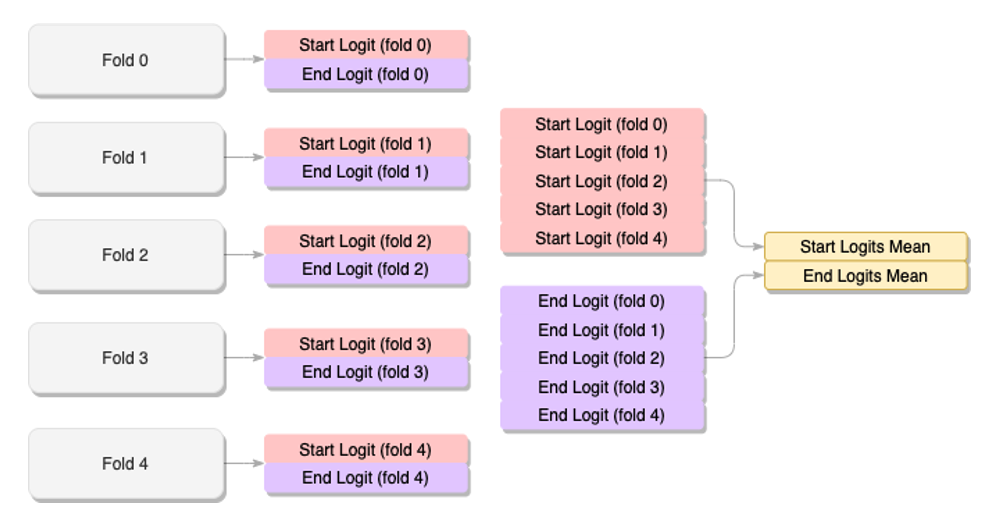
하지만 Public Leaderboard 기준으로 KFold 를 수행한 결과가 단일모델 대비 2점 가량 낮은 67.500 를 기록하였습니다. 실제 Private Leaderboard 결과에서도 단일모델보다 성능이 떨어졌습니다. 그 이유로는
- Random 하게 fold 를 나눈 것에서 모델의 학습 성능이 저하되었을 수 있다.
- Fold 별 모델의 Hyperparameter 를 다르게 설정하였으면 더 좋은 결과가 나올 수 있었을 것이다.
위의 두 가지를 예상해볼 수 있었고, 각 fold 별로 다시 hyperparameter 를 tuning 하고 재학습시키는 것에는 너무 오랜 시간이 걸리기 때문에 KFold 의 성능을 더 개선하기 보다는, 이미 예측한 결과들을 Ensemble 에 사용하기로 하였습니다.
Ensemble
저희는 처음부터 Ensemble 을 고려하였기 때문에 위와 같은 다양한 실험들을 하면서 inference 의 결과들을 꾸준히 모아두기로 하였었고, 결과적으로 약 150개의 inference 결과를 모을 수 있었습니다. inference 를 통해 나오는 파일은 아래와 같습니다.
- 질문에 대해 예측한 정답들 중 확률값이 높은 20개의 정답, start/end logit, 그리고 확률값을 저장하는 n_best_predictions.json 파일
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17{
"mrc-1-000653": [
{
"start_logit": 4.3632707595825195,
"end_logit": 3.9985079765319824,
"text": "사락사라",
"probability": 0.5359510779380798
},
{
"start_logit": -5.266266345977783,
"end_logit": -3.9985079765319824,
"text": "지구에서, 사락사라",
"probability": 0.21724958717823029
},
.
.
. - 각 질문 별로 가장 높은 확률 값을 가지는 정답만 저장하는 predictions.json 파일
1
2
3
4
5
6
7
8{
"mrc-1-000653": "40억년전 지구",
"mrc-1-001113": "냉전 종식",
"mrc-0-002191": "빌헬름 미클라스",
.
.
.
}
저희는 약 150개의 pair 중에서 public leaderboard 기준 EM score 가 60 이상인 96개의 prediction, nbest_prediction 를 활용하게 되었습니다.
Soft Voting
첫번째 방식은 모델들의 n_best_predictions에서 같은 정답들의 probability를 합하여 가장 probability가 가장 큰 정답을 선택하는 soft voting 방법이었습니다.
아래 그림과 같은 두 예측 결과를 사용한다고 할 때, 두 모델의 “사락사라” 라는 예측값의 확률을 더한 결과가 약 1.5987로 가장 높아 “사락사라”를 첫번째 질문에 대한 정답으로 선택하는 방식입니다.

Soft Voting 방식으로 Public EM 62점 이상의 30개의 결과를 앙상블한 결과 약 3점 정도 상승한 72.080 의 EM Score 를 기록할 수 있었습니다.
성능을 더욱 높이기 위하여 모델의 결과를 분석해본 결과, 단일 모델 성능이 높아질수록 다른 모델들에 비해 정답의 probability 가 높은(확신을 하는) 경향이 있었습니다. 이러한 모델들은, 정답을 결정하는데 오히려 확증편향이 생길 것으로 예상하였고 영향력을 감소시키기 위해 probability가 threshold 값 이상이면 clipping 하는 방법도 이용해보았지만 큰 효과를 볼 수 없었습니다.
Soft Voting 에 사용한 코드는 아래와 같습니다.
1 | |
Hard Voting
두번째 방식은 모델들의 predictions.json 파일들을 합쳐, 가장 많이 등장한 정답을 최종 정답으로 선택하는 방법이었습니다. 하드 보팅의 경우 LB상 Public EM 성능이 soft voting에 비해 높지 않았습니다.
이를 개선하기 위하여, Voting 후 1위와 2위의 득표(점수)의 차이가 Threshold 이하 일 경우 각 후보 단어들의 비교를 진행하여, 다른 단어의 sub string인 경우 해당 단어와 substring 의 길이의 비율만큼 얻은 점수를 더해 주는 Rule base 알고리즘을 수행하였습니다.
1 | |
Voting 이후 위와 같은 결과를 얻었다고 했을 때, “냉전”은 “냉전 종식”의 sub string이므로 “냉전 종식”의 20점의 일부분을 추가로 얻게 됩니다. 그 결과 “냉전”은 “냉전 종식” 보다 더 많은 점수를 가지게 되어 최종 정답은 “냉전”이 되도록 하였습니다.
단순 hard voting 을 적용하였을 때는 Public EM 기준 70.000 을 기록하였으나, 해당 방식을 사용하여 71.250 으로 향상시킬 수 있었습니다.
1 | |
최종 제출
Leaderboard 의 score 차이가 크지 않은 soft voting 결과와 hard voting에 rule base 알고리즘을 수행한 결과에 후처리를 적용하여 최종 제출물로 선택하려고 했습니다. 후처리는 정답 중 ‘이’, ‘에’와 같은 조사로 끝나는 정답들에 대해 konlpy의 POS tagger를 이용하여 정답에서 조사를 제거해주었습니다.

마지막에는 서버상 오류로 soft voting한 결과는 제출하지 못하였지만, hard voting 결과가 public leaderboard 점수보다 오히려 상승한 EM 71.670, F1 81.400 을 기록하며 최종 3위를 기록할 수 있었습니다.
나중에 확인해보니 soft voting 결과는 오히려 60점 대로 떨어졌습니다.
시도했으나 잘 안된 것들
Generative Reader
QA 과제를 해결하는 데엔 Query와 Passage를 바탕으로 적절한 토큰을 생성해 답을 만드는 Generative Reader를 활용할 수 있습니다. Baseline 성능 평가 당시 Generative Reader 를 사용한 Validation Score 가 Extractive 방식보다 낮았기 때문에 집중적으로 활용하지 못했습니다. 하지만 영어에서는 Extractive 보다는 Generative 방식이 성능이 좋다고 알려져있으며, 과제의 답안들이 Passage 내에 추출 가능하게 존재하고, Reader가 산출한 답안과 정답간의 EM을 통해 평가하는 특성상, Extractive Reader보다 좋은 성능을 기대하기 보단 앙상블 과정의 다양성 확보를 목표로 Generative Reader를 꾸준히 시도해보았습니다.
Model input 형식은 [질문] : {question} [지문] : {passage} 형태이며, max_sequence_length 를 초과하는 경우 정답을 포함한 passage 임을 알 수 있게 special token 을 활용하여 정답을 포함하는지, 포함하지 않는지 표기하였습니다. Prediction 단계에서는 Beam Search 를 사용하여 Output 을 생성해냈고, inference 를 위해 Extractive Reader가 답안이 있을 걸로 예상되는 위치들의 Logit 값을 통해 최종 Prediction을 선정했던 데에 착안해서, 모델이 답안을 생성하며 사용한 확률값을 기준으로 사용하여 후처리를 진행했습니다.
이 과정에서 input sequence length의 길이를 줄여 한번에 모델이 읽는 지문의 양을 줄이는 시도를 하게 되었고, 결과적으로 Validation Metric 기준으로 EM: 40, f1: 47 정도로 성능을 향상시킬 수 있었습니다.
다만, 어느정도 긴 호흡으로 지문을 해석해야 정답을 도출할 수 있는 경우, sequence length가 길게 주어졌을 때 잘 맞추던 질문을 낮은 sequence length에서는 맞추지 못하는 사례들이 존재하였으며 Extractive Reader 에서 많은 성능을 이끈 Negative Sampling 을 도입하니 정답이 없는 input이 훨씬 많아지고 성능이 더욱 감소했습니다.
이러한 이유들로 Generative Reader 는 최종적으로 활용되지 못했습니다. 추가적으로 학습시킨 Generative Model 을 HuggingFace의 EncoderDecoderModel 구조의 Decoder 로 불러와 Extractive 와 합치는 모델링 작업을 시도했으나 구현상의 미숙함들과 실수로 인해 실험을 더욱 이어가지 못했습니다.
Retro Reader
Retro Reader 는 SQuAD2.0 Benchmark 에서 EM 기준 7위에 Rank 되어 있는 모델입니다.
Retro Reader 의 논문 Retrospective Reader for Machine Reading Comprehension 을 살펴보면, Answerable 을 판별하고 정답을 예측하는 Sketch Reader 와 정답을 예측하는 Intensive Reader 로 구성되어 있으며, 이들의 예측값을 바탕으로 Decoder 에서 최종 정답을 예측하는 방식입니다.
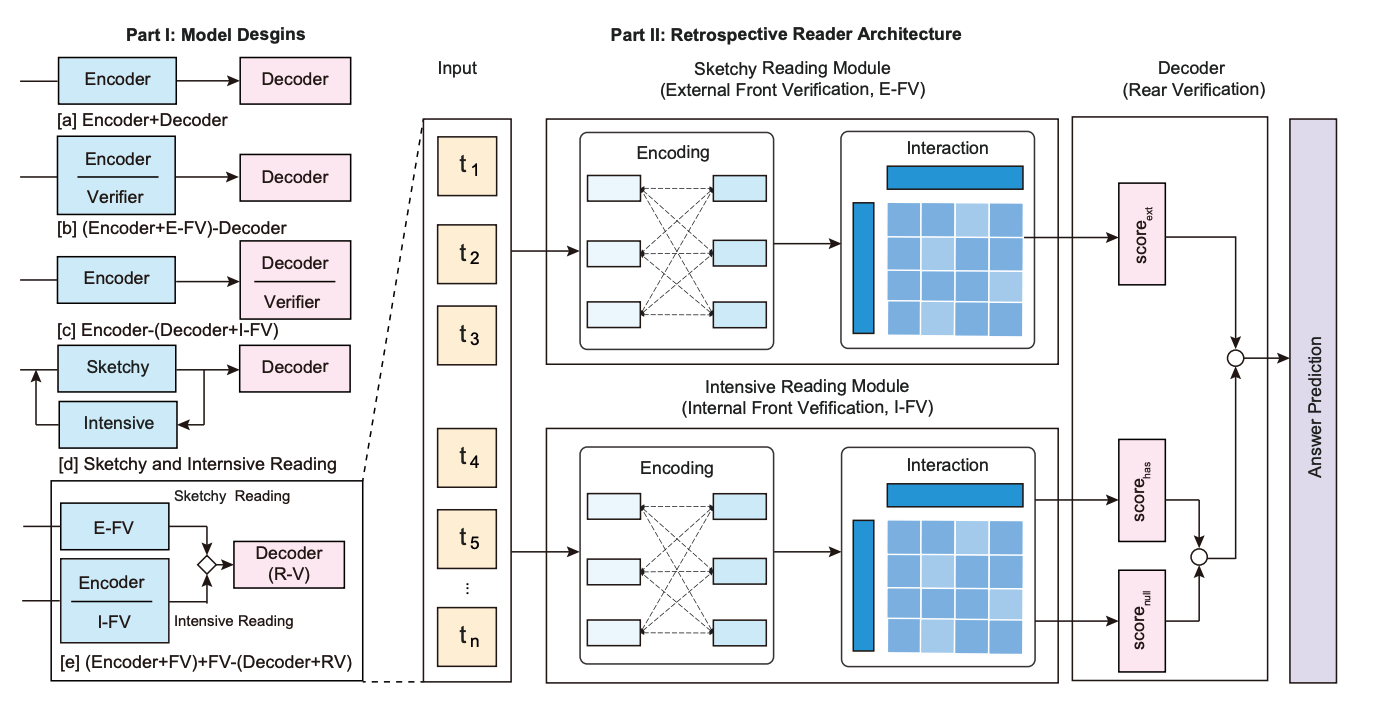
해당 방식의 Github AwesomeMRC 을 참고하여 구현을 시도해보았지만 Huggingface 의 transformers 버전이 매우 낮아서 Porting 하여 사용하기에는 레거시가 많이 존재하였습니다. 또한 No Answer 에 대한 데이터셋을 따로 구축했어야 했는데, 이 때 Dataset 의 Scale 을 어떻게 조정해야할지 정하지 못했습니다. 단순하게 생각해보면 Train dataset 의 전체 질문들에 대해 Ground Truth 를 제외한 모든 Wiki 의 Passage 를 붙일 수 있었고, 양을 조절하여 Random 하게 No Answer Passage 를 뽑아올 수 있었으나 정확한 기준을 세우지 못하였으며 또한 Question Generation, AEDA 등으로 증강한 데이터셋을 활용하였을 때 학습 시간만 오래 들고 별다른 성능 향상을 보지 못했기 때문에 생각만 하고 시도하지 않았습니다.
다시 생각해보면 충분히 시도할만한 가치가 충분히 있었으나, 아쉬움이 남습니다.
Focussing on surrounding sentences of the answer
Data Augmentation 과 Custom Head 를 부착한 방식으로 이미 큰 성능 향상을 보았지만, 모델 구조를 더욱 개선할 필요를 느끼게 되었습니다. 현재 Inference 시 Retrieval 로 20 개의 질문과 유사한 문서를 찾아오도록 하는데, 이 문서들의 순서를 바꿀 때마다, 그리고 20개보다 더 많은 문서를 찾아오도록 할 때마다 모델이 다른 정답들을 예측했기 때문입니다. 따라서 Reader 가 더욱 일관된 답변을 예측할 수 있도록 하기 위해 고민하던 중 아래의 문서와 논문에서 아이디어를 얻을 수 있었습니다.
Reader 가 정답을 예측할 때 정답인 것으로 예측되는 문장과, 주변 sentence 에 집중할 수 있도록 하면 Retrieval 이 아무리 많은 문서를 가져오더라도 오답률이 줄어들 것이다.
이 아이디어를 구현하기 위해 두 가지 방법을 떠올리게 되었습니다.
- Sentence BERT 를 사용하여 Question 과 Passage 에 대한 Embedding 을 RoBERTa Embedding 에 더해주자.
- Question 과 Passage 에 대한 Embedding 으로 Cosine Similarity Score 를 구하고, 해당 Score 를 weight 로 하여 RoBERTa 의 last hidden state 에 곱해주자.
Similarity Embedding
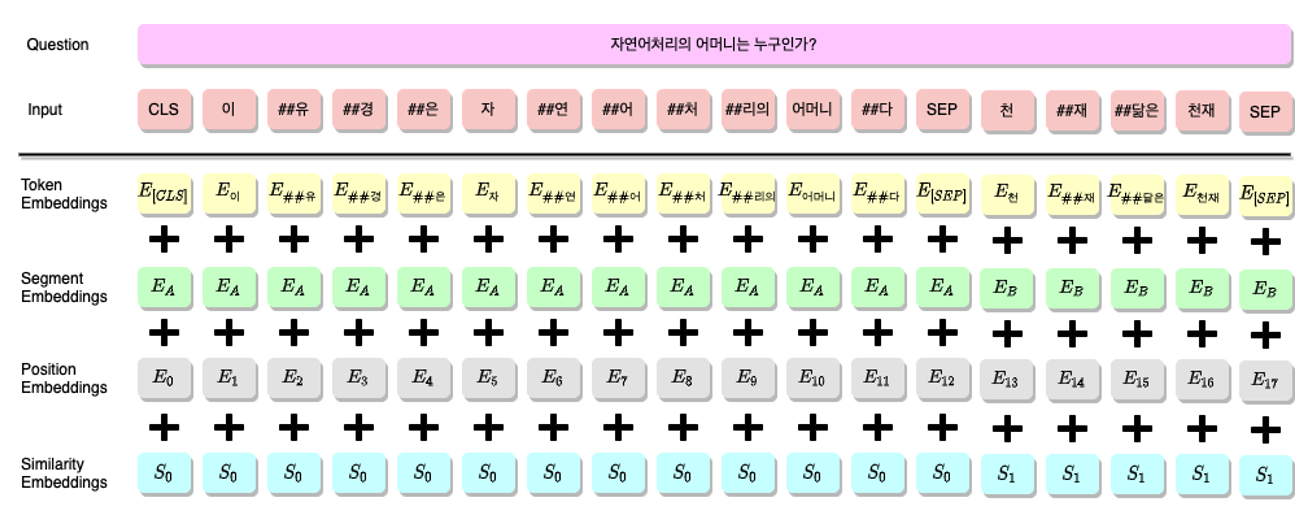
Huggingface 의 RobertaEmbeddings 를 살펴보면 BERT 의 구조와 동일하게 Token Embeddings, Segment Embeddings, Position Embeddings 를 모두 더한 뒤 LayerNormalization 과 Dropout 을 취한 Embedding 을 반환합니다. 이 때 Sentence Transformer 로 계산한 Query 와 Passage 의 Embedding 을 더해주면, 단순히 유사도를 포함한 Embedding 을 고려할 수 있을 것이란 생각을 했습니다.
1 | |
하지만 embedding layer 에 다른 모델의 embedding 값을 더해주니 이미 사전학습된 backbone 의 embedding 값들이 망가지며 제대로 학습이 이루어지지 않았습니다. 최대한 similarity embedding 을 backbone 의 embedding 과 유사하게 맞춰주기 위하여 embedding dimension 에 따라 표준편차 등을 이용하여 scaling 도 진행해봤으나 역시나였습니다. Scratch 부터 재학습 시킬 수 있는 시간과 자원이 없었기 때문에, 다른 방법을 몰색했습니다.
Similarity Weight Layer
Embedding Layer 를 수정하여 재학습시키는 것 대신에 Sentence BERT 를 사용하여 얻은 Question, Passage Embedding 으로 코사인 유사도를 구한 뒤 해당 유사도들을 backbone 의 last hidden state 에 weight 을 주는 방식을 시도해 보았습니다. 해당 아이디어는 Extractive Summarization as Text Matching 를 통해 얻게 되었습니다.
Summarization Task 의 Content Selector 방식에서는 중요 문장들의 후보를 추린 이후에 해당 문장들만을 통해 요약문을 생성하게 됩니다.
처음에는 이처럼 정답을 찾을 수 있을 것 같은 문장들의 후보를 추린 이후에 전체 passage 가 아닌 그 문장들에 대해서만 정답을 찾게 하는 방식을 시도했었는데, Summarization 에 대한 이해와 기본기가 부족했으며 시간적 여유도 없었기에 포기하게 되었습니다.
따라서 정답을 찾을 수 있는 문장들의 후보가 아닌, 유사도를 기반으로 질문과 유사한 문장들에 대해서 가중치를 주는 방식을 생각해내게 되었습니다. 아이디어의 검증은 저희팀의 든든한 멘토님이신 이유경 멘토님께서 도와주셨으며 hidden state 에 대해서 가중치를 주는 방식만 보았을 때는 틀린 접근이 아니라는 말씀을 주셨기 때문에 걱정없이 시도해볼 수 있었습니다.
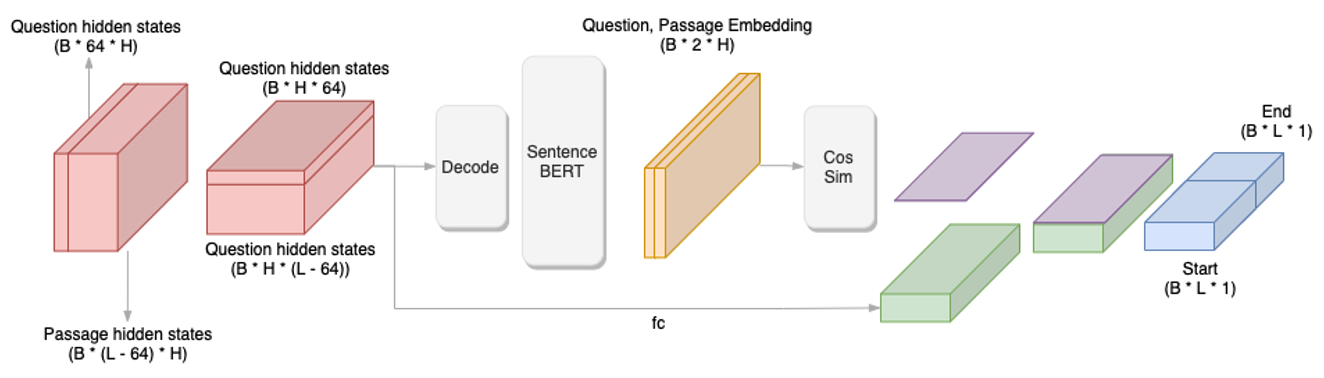
과정을 간략하게 풀어쓰면 아래와 같습니다.
학습 데이터의 평균적인 질문 길이는 60 정도였습니다. 전처리 여부나 스페셜 토큰을 고려하여 Backbone 으로부터 나온 Sequence Output 에 64 채널을 기준으로 Question, Passage hidden state 로 분리한 뒤 SEP 토큰이 있는지 조사합니다. SEP 토큰이 있었다면 질문이 포함되어 있는 것이므로, 이 때는 Decoding 을 진행한 후 Sentence BERT의 Bi-Encoder 를 사용하여 Question 과 Passage 의 임베딩을 생성합니다. 이 임베딩을 통해 코사인 유사도를 계산한 뒤 정규화와 scaling 을 진행한 후 이것을 weight 로 하여 dense layer 를 통과한 hidden state 에 곱해주고, 그것을 최종 output logit 으로 반환합니다.
하지만 돌아가게끔 만드는 것 만으로도 어려움이 많았고, 구현 과정에서 실수가 있었는지 학습이 제대로 이루어지지 않았습니다.
어떻게든 돌아가는 코드를 작성하고 학습이 이루어지지 않는 것을 보았을 때 굉장히 아쉬움이 많이 남았지만, 대회 막바지였기 때문에 해당 방법은 포기하게 되었습니다.
APE (Adaptive Passage Encoding)
아이디어를 얻은 논문은 아래와 같습니다.
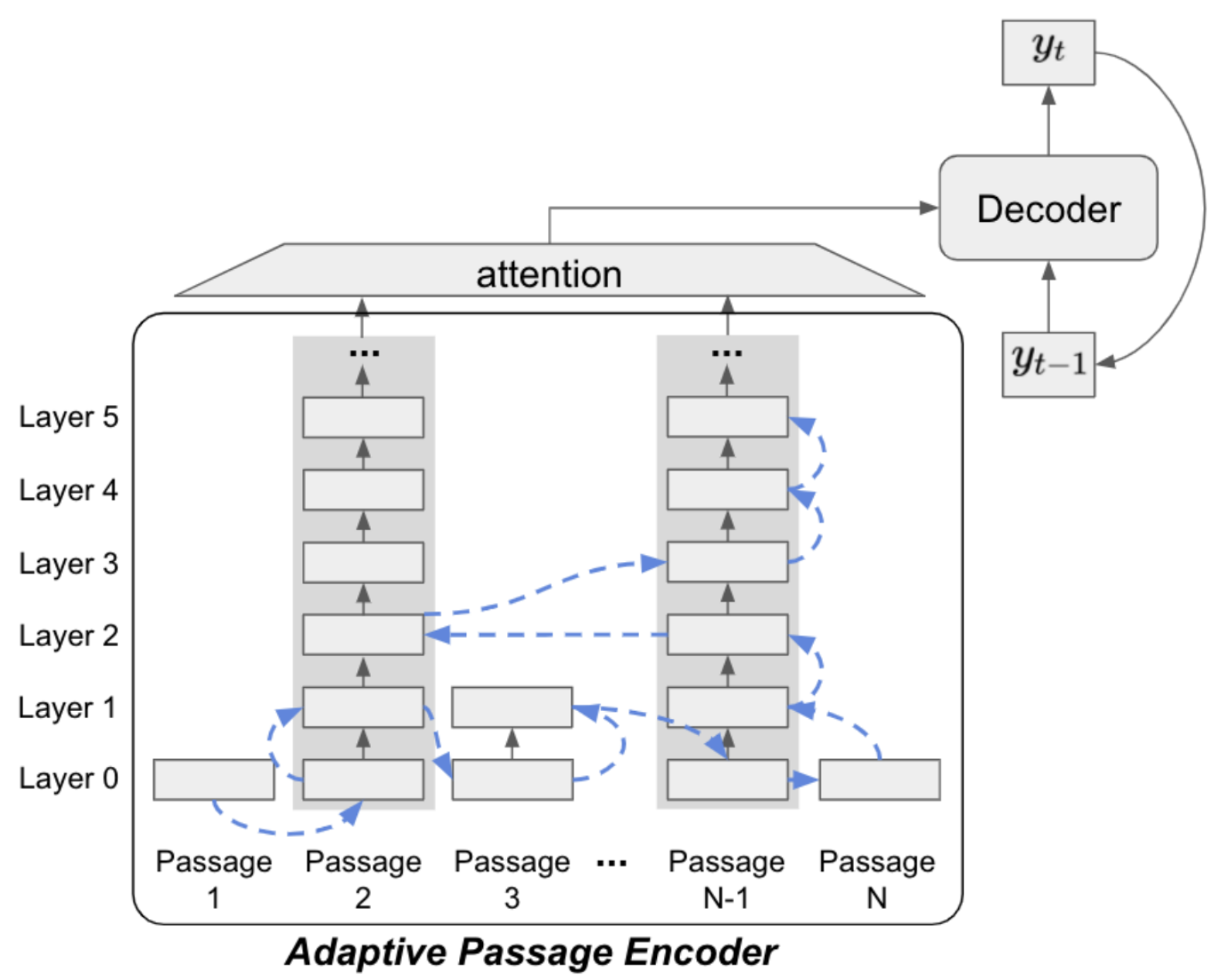
APE 방식은 질문에 대해 Retrieval 이 수행한 n개의 Passage 에 대하여 Pruning 방식으로 적절한 Passage 로 여겨지는 Candidates 를 추리고, 해당 Candidates 에 Attention 을 수행하는 방법입니다.
위에서 시도한 Focussing on surrounding sentences of the answer 방법보다 훨씬 우아한 방식이라고 생각했기 때문에 해당 논문의 APE Github 을 참조하여 시도해보려고 했습니다. 하지만 Facebook 의 오픈소스인 FiD 에 의존성이 걸려있고, Generative 모델인 T5를 사용하며 Huggingface 의 transformers 버전도 3.0.2 로 매우 낮았기 때문에 한국어로 사용가능한 MT5 나, Extractive 방식으로 porting 하기엔 상당히 어려움이 있었습니다. 또한 이 논문을 알게 된 시기가 대회 종료 2일 전으로, Ensemble 을 수행하지 못한 상황에서 시도하기에는 시간적인 여유도 없었습니다. 추후에 영어로 ODQA 에 도전하게 된다면, APE 를 0순위로 시도해보고 싶다는 생각을 하게 되었습니다.
마지막으로
전반적으로 KLUE-RE 대회때보다 팀원들 모두가 성장했음을 조금이라도 느낄 수 있었고, 특히 실험을 진행하면서 문제점을 파악하고 문제를 정의하며 해결하는 과정에서 많은 즐거움을 얻을 수 있었습니다.
저희의 이야기가 조금이라도 도움이 되었길 바라면서 마치겠습니다.
긴 글 읽어주셔서 감사합니다.