KLUE - Relation Extraction
청계산셰르파의 KLUE-RE 등반일지
약 12일동안 참여했던 P Stage의 KLUE - Relation Extraction 대회의 Wrap up Report이자 회고록입니다. 철저한 기록과 공유에 공감한 7명의 팀원이 처음 합을 맞추었기 때문에 어설픈 점도 있었지만, 그간의 생생한 기록들을 바탕으로 어떻게 서로가 서로의 셰르파로써 등반을 완료할 수 있었는지 저희의 경험을 나누고자 합니다.
물론 미흡한 점도 있었고, 여러 시행착오를 겪었지만 결과적으로는 팀원 모두가 만족한 협업이었다는 점에서 지난 대회보다 많은 성장을 할 수 있었다고 느낄 수 있었습니다. 저희의 경험이 어떠한 형태로든 도움이 되고, 좋은 레퍼런스가 되기를 바라며 시작해보도록 하겠습니다.
목차
⚔️ 팀 소개
⛰ 청계산셰르파


저희는 캠프 기간동안 모든 것을 생생하게 기억하고 나누는 기록과 공유라는 가치에 공감한 7명이 모여 팀을 구성했고, 서로가 서로의 가이드로서 좋은 영향을 주고받을 수 있는 셰르파가 되기를 원했습니다.
또한 주니어 엔지니어들의 로망은 판교역 근처 회사들에서 일을 하는 것입니다. 저희는 판교역의 뒷산인 청계산을 부스트캠프 과정에 빗대어 완벽하게 등반해보겠다는 의미로 청계산과 셰르파를 더해 청계산셰르파라는 이름을 사용하게 되었습니다.
👨👨👦👦 청계산셰르파들
-
이요한
-
문하겸
-
전준영
-
정진원
-
김민수
-
정희영
-
곽진성
🔎 대회 개요
이번에 참여한 대회의 과제는 문장 내 개체간 관계 추출 과제로, 문장의 단어(Entity)에 대한 속성과 관계를 예측하는 자연어 처리 과제입니다. 관계 추출은 비구조적인 자연어 문장에서 구조화된 정보를 추출하는 데에 목적을 두고 있습니다.
저희가 사용한 데이터셋은 「KLUE: Korean Language Understanding Evaluation」(Park et al., 2021)을 통해 공개된 KLUE-RE 데이터셋으로, KLUE 데이터셋을 사전학습한 RoBERTa를 fine-tuning하여 베이스모델로 사용하였으며, private leaderboard에서 f1 score 기준 19팀 중 5등, auprc 기준 19팀 중 2등을 기록하였습니다.
🥈 Final Score
- micro F1 score: 73.732 (19팀 중 5등)
- AUPRC score: 82.964 (19팀 중 2등)
🤝 협업
🥾 사전논의
RE 대회가 시작하기 1주일 전부터, 저희는 미리 대회를 위한 전략들을 구상했습니다. 서로의 스타일을 모르기에 당장은 결정이 안나더라도, 세부적인 사항들에 대한 논의를 단 한번이라도 거쳤던 것은 추후에 의사결정속도와 팀원들의 만족에 있어서 큰 영향을 끼쳤습니다.
대회 전 논의사항들
프로젝트관리 툴/채널 정하기
- ex) Github project의 kanban board, notion, slack, zoom, google meet, git page, github action 등등
- 카카오톡 (슬랙보다 많이 접함.) 슬랙처럼 스레드 형식의 대화를 할 수 없음.
- 중요한 이슈가 생기면 슬랙에도 같이 이야기하자.
코드명세서 or 컨벤션
- naming
- 클래스, Static Vars = CamelCase
- 변수명, 함수명 = snake_case
- formatting (& auto formatter)
- autopep8
- black, yap…
- annotation
- ‘’’ docstring ‘’’
- VSCODE CODE_ANCHORE
- TODO, NOTE,
- docstring을 알아서 해주는 게 있는지 서치해보기!
- 필요한 내용만 작성할 수 있도록 룰을 추가로 정할 것.
주석은 영문으로!!
indentation (tab 1 or space 4)- 그 외 vscode extensions
- git graph, git lens
- Live share
- naming
가상환경이나 환경관리 전략 (zsh, dotenv, … conda, pip …)
- conda 사용!
미정
- 브랜치를 어떻게 만들어놓을것인가 (실험전략까지 고려)
다른사람들이 checkout만으로 동일한 실험을 할 수 있게 하기 위함
MAIN- DEVELOP
유저편의성, 코드기능개선, 버그픽스 접두어/feature - BASELINE
접두어/feature x 실험 o
다른 태스크에 대한 것들이나 (실험위주)
baseline/qa/1
baseline/ner
baseline/sentence classification
- DEVELOP
- 너무 브랜치가 많아질 수 있다.
- config를 변경하면 브랜치를 분기하지 않을 수 있다.
- 브랜치를 어떻게 만들어놓을것인가 (실험전략까지 고려)
(선택사항) 여유가 되면 자세하게 써놓기
커밋전략
- commit message 규칙이나 템플릿 정하기
(작업단위와 리뷰에 대해서 더 생각해보기)
PR 템플릿 및 PR/Review 전략 구체화
- PR 올리는 타이밍(시점)
- 성능향상에 의한 PR은 모두가 리뷰
- 자잘한 변화들은 책임자만 리뷰
- 리뷰를 어떻게 할 건지? 리뷰어는 몇 명
- 속도? Merge속도에 대해서 데드라인이 있었음 좋겠다.
- PR 올리는 타이밍(시점)
그라운드룰 및 빠른 의사결정을 위한 협업가치 리스트업 및 우선순위 정하기
- ex) 안정성(예외처리), 구성원의만족, 가독성, 일관성, 객체지향성, 단순성, 외부유저의경험, 신속성(작업속도), 통제가능성, 학습가능성, 취업적용가능성, 실험가능성 등등
또한 이러한 사전논의를 통해 대회가 진행될수록 팀원들이 무엇을 원하는지 확실히 알 수 있었으며, 모두가 같은 그림을 그리고 같은 방향을 가지고 대회에 임할 수 있었습니다.
이러한 노력을 토대로 저희는 빈틈없이 기록을 이어가고, 실험을 공유하며 항상 새로운 실험아이디어를 얻을 수 있었습니다. 그 결과 하루에 10번씩 제출가능한 대회에서 12일 동안 다른 팀들 대비 압도적인 횟수인 99번의 실험결과를 제출 해볼 수 있었습니다.
⚙️ 협업툴
지난 대회 때 다양한 협업 채널을 구성하였을 때 오히려 혼란이 가중되고 모든 채널을 사용하기 힘들다는 점을 고려하여, 대부분의 협업을 Notion으로 진행했습니다. 또한 불가피한 상황에 대비한 연락수단으로 kakaotalk과 slack을 사용하였고, git은 사용가능한 기능을 최소한으로 하고 코드관리 수단으로만 사용하였습니다.
Notion에서 일정관리, 문서관리, 실험관리 등 많은 기능을 사용하기 위해 엄밀하게 Template을 찾아보며 Dashboard를 구성하였고 그렇게 아래와 같은 페이지를 구성할 수 있었습니다.
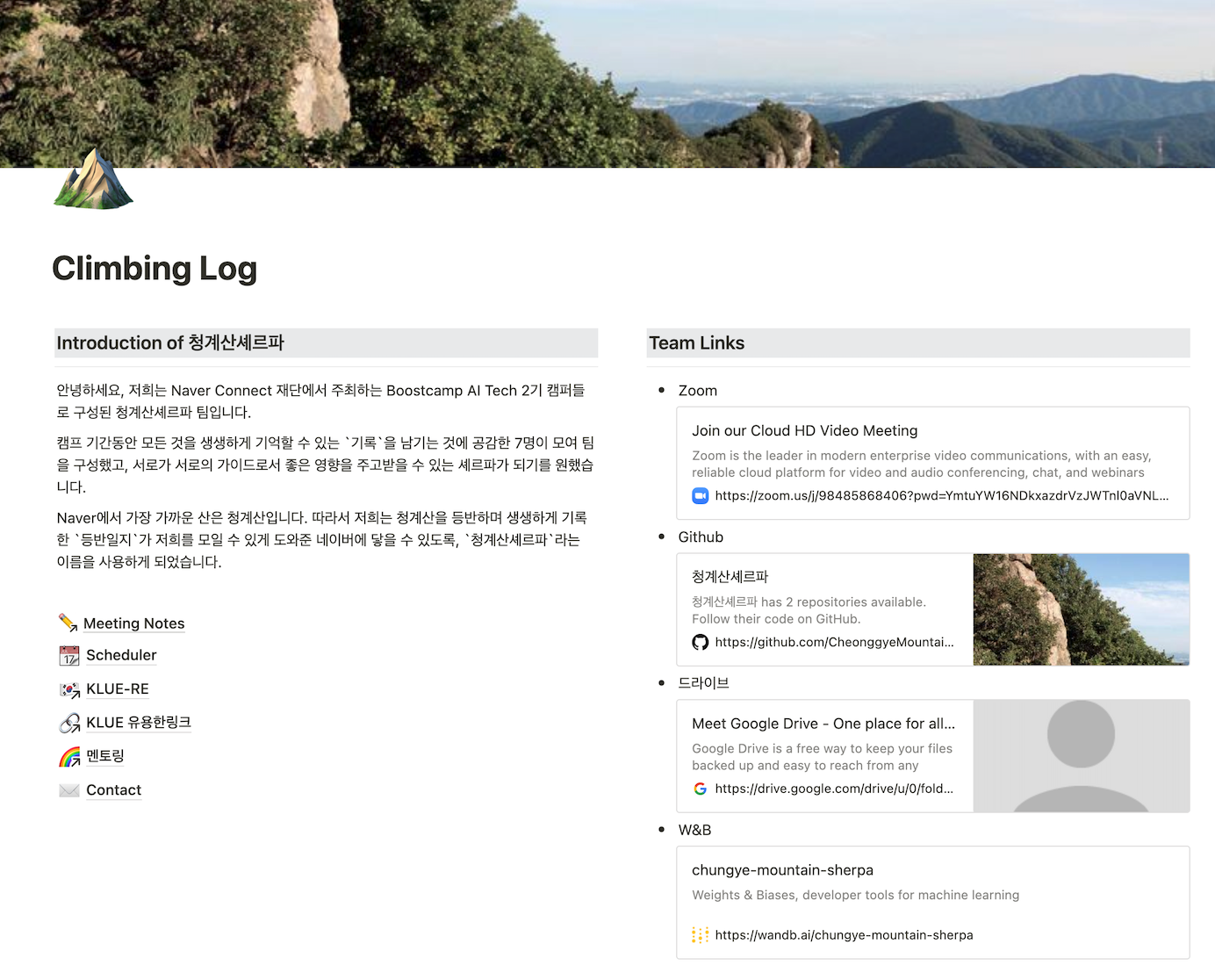
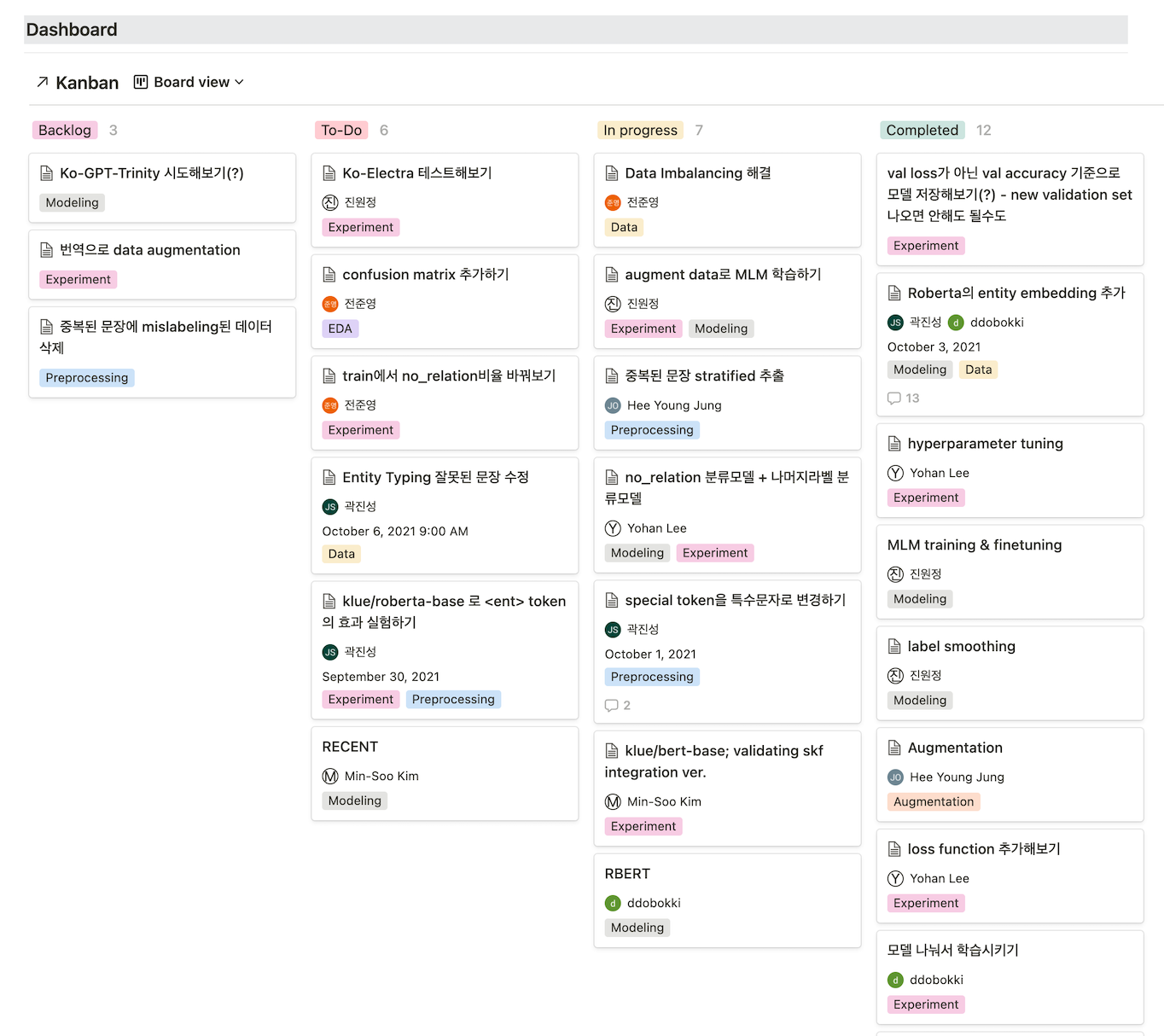
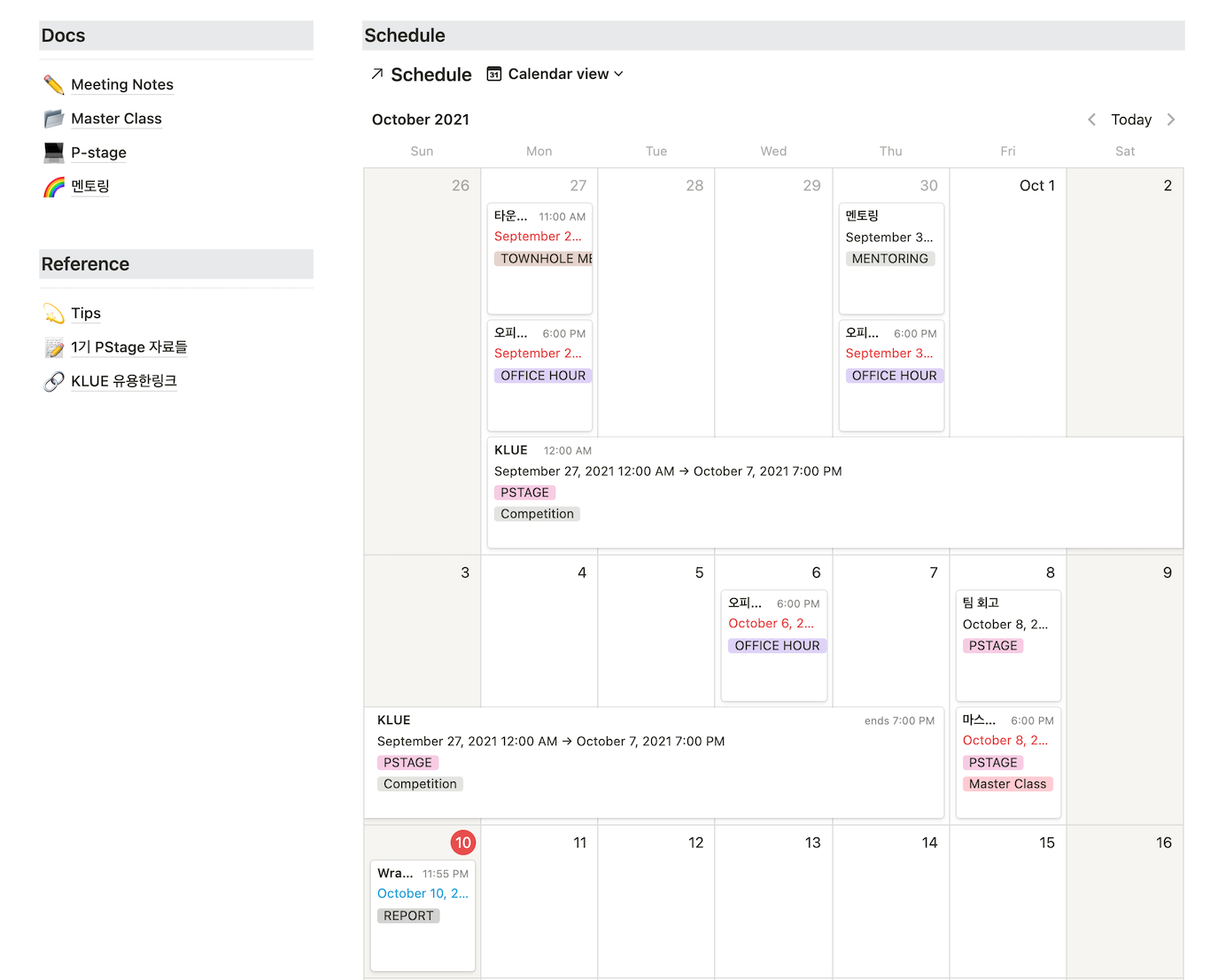
Main Dashboard
sub page들의 link와 zoom, wandb, github, drive 링크들
TODO와 실험관리를 위한 kanban 보드
실험을 위한 Process별 Tag 부착

Assignee 할당
일정관리를 위한 schedule
- 알림기능 활성화
- 용도별 Tag 부착
Reference와 Docs 링크들
- 회의록
- 멘토링
- 연구일지 등
💻 코드 관리
초반에는 전체 코드를 관리하기 위해 PR-Merge 방법으로 진행하다가 Review가 늦어지거나, 작업시간이 오래걸리면 다른 팀원이 같은 작업을 하는 등 예상치 못한 병목이 발생하고 오히려 개인 실험에 방해요소로 작용할 수 있다는 판단을 하게 되었습니다.
따라서 baseline으로 사용할 수 있는 코드에서 각자의 이름 혹은 실험 이름으로 분기를 나누어 개인 작업을 진행하면서, 사전에 논의했던 것처럼 score가 올랐을 경우에만 baseline 코드에 PR-Merge를 하고, 해당 score를 재현가능할 수 있게끔 버전업하기로 했습니다.
branch가 많아지긴 했지만, 실험에 실패했을 때 빠르게 Rollback할 수 있었고, 각자의 실험에서 확실한 성능향상 요소만을 합칠 수 있었습니다. Competition이라는 플랫폼의 특성상 7명의 팀원이 각자 작성한 모든 코드들을 Review하고 합치면서 작업을 이어나가기에는 많은 시간과 노력을 필요로 했습니다. 하지만 기준을 두고 필요할 때만 코드를 병합하니 실험은 실험대로 잘 이루어지고, 실험에 실패하더라도 가장 최신버전의 코드를 모두가 사용할 수 있었다는 점에서 많은 이점을 얻을 수 있었습니다.
🧑🔬 체계적인 실험
저희는 Kanban board를 사용하여 실험을 관리하였습니다.

Backlog, TO-DO, In progress, Completed 네 단계로 나누어 서로가 어떤 실험을 진행하고 있는지, 어떤 실험을 해야하는지 파악할 수 있게 하였으며 실험이 끝날 때마다 그때그때 갱신하는 작업을 진행하였습니다.
각각의 카테고리 별 책임은 이렇습니다.
- Backlog: 단순 실험 아이디어 및 건의사항, 수정사항
- TO-DO: 꼭 적용해봐야 하는 실험
- In progress: 현재 진행중인 실험
- Completed: 완료된 실험
Backlog에 진행해보고 싶은 실험카드가 생겼거나, 다른 실험 아이디어가 생긴 경우에는 Notion의 Comment 기능을 이용하여 이미 진행중인 실험이면 해당 실험의 진행상황이나 주의사항들을 더 자세하게 공유할 수 있게 하였습니다.


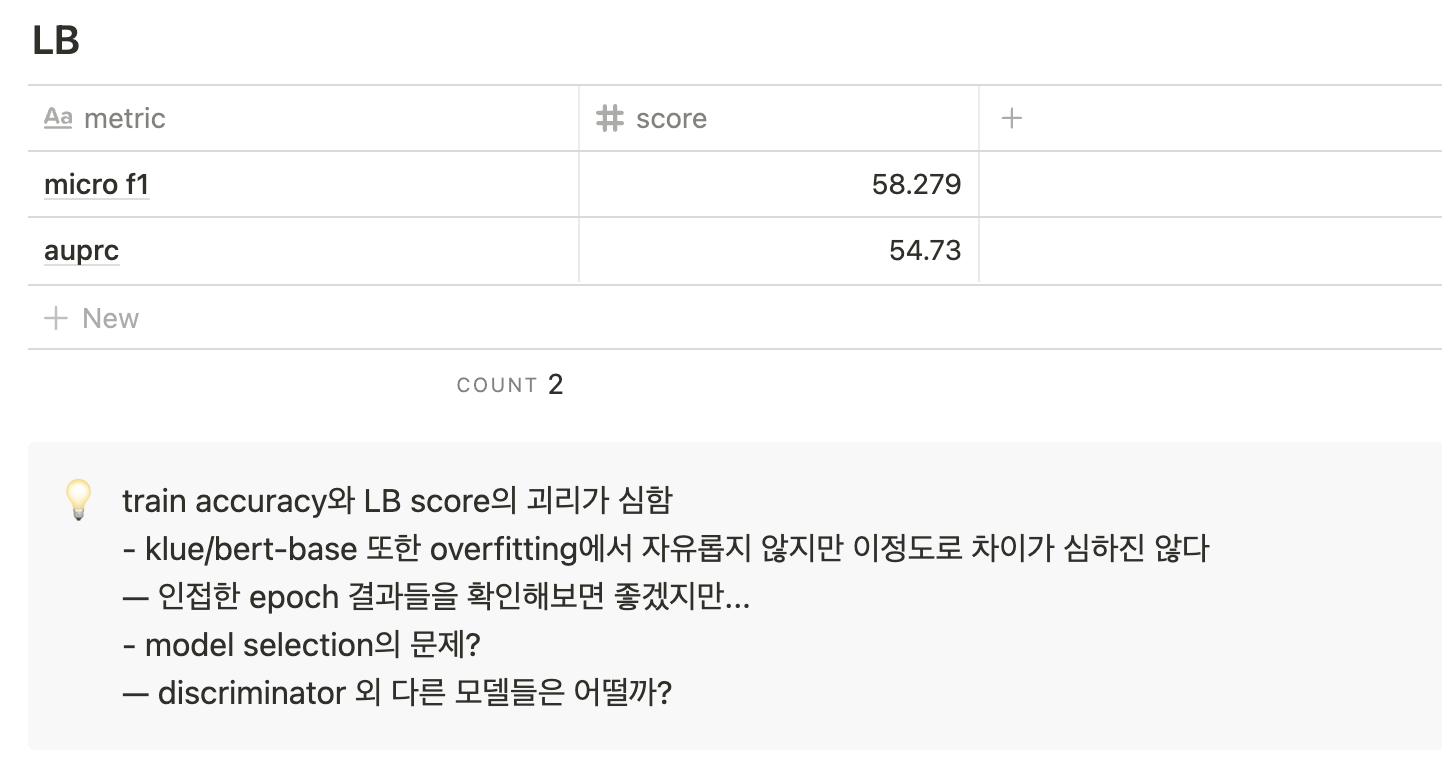
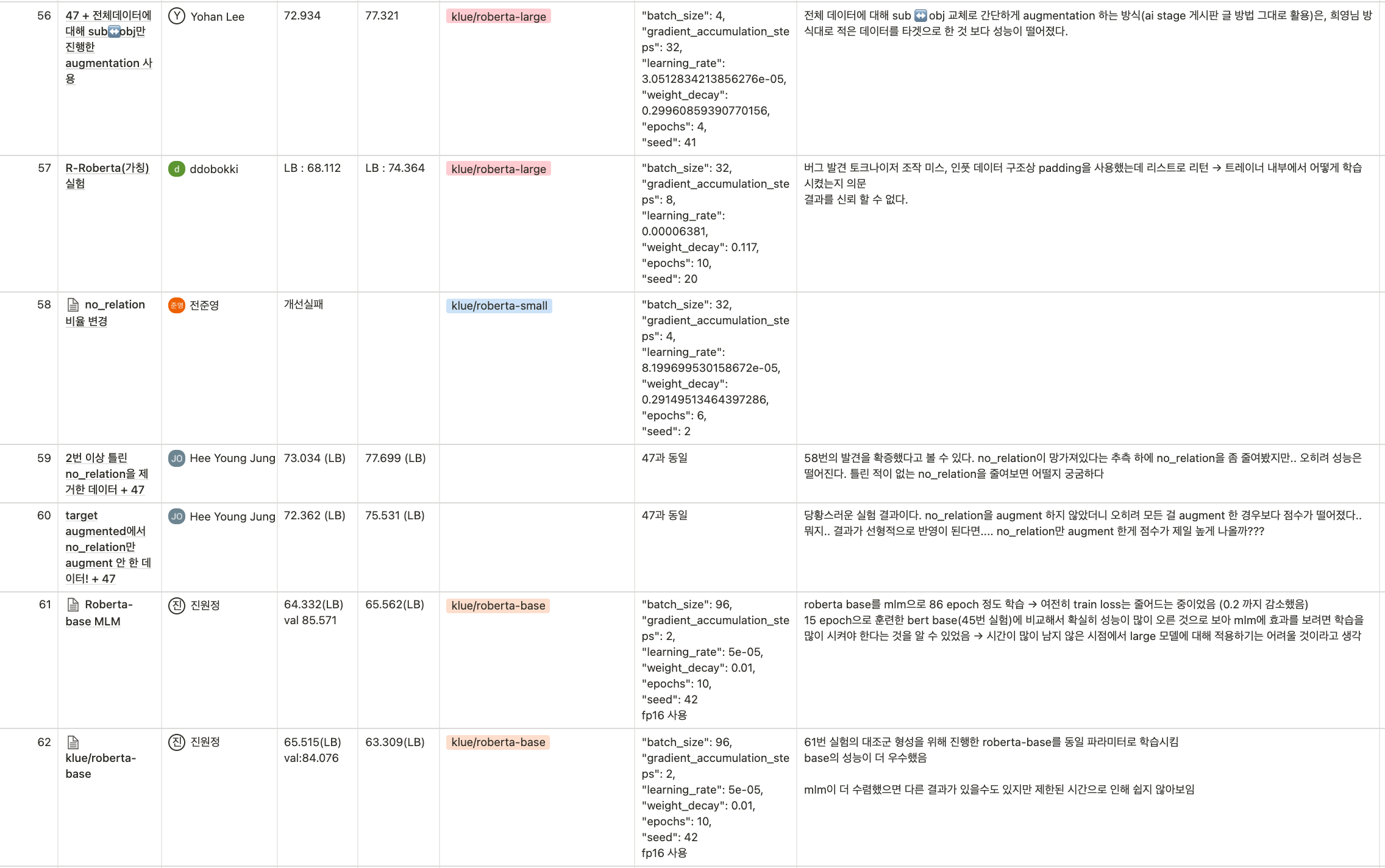
실험카드가 Completed로 이동하게 되면 아래와 같이 실험기록표에 결과를 작성하고, 실험의 성공여부와 관계없이 그 실험에 대한 평가와 그런 결과가 나온 이유 혹은 주의사항 등을 기록하게 하였습니다.
🛋 Data Experiments
👁 Data EDA
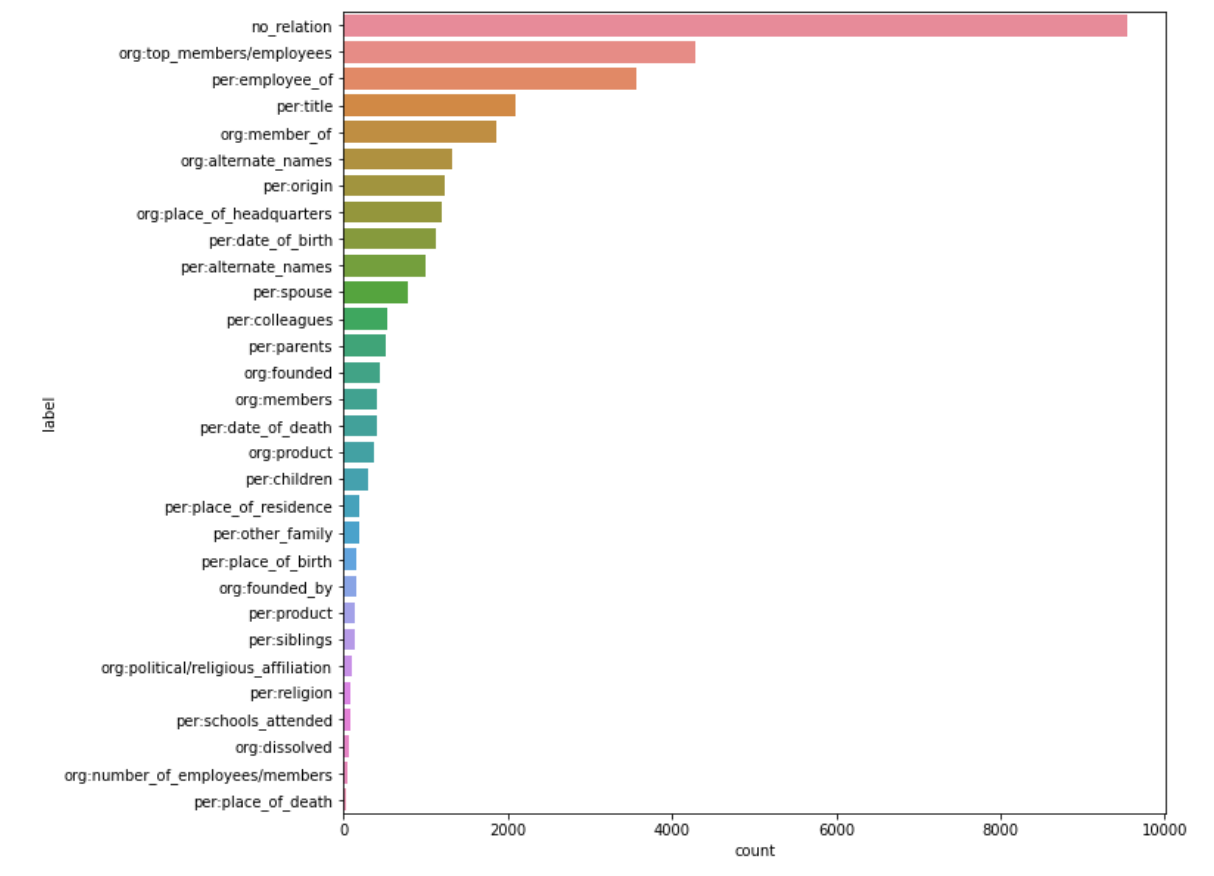
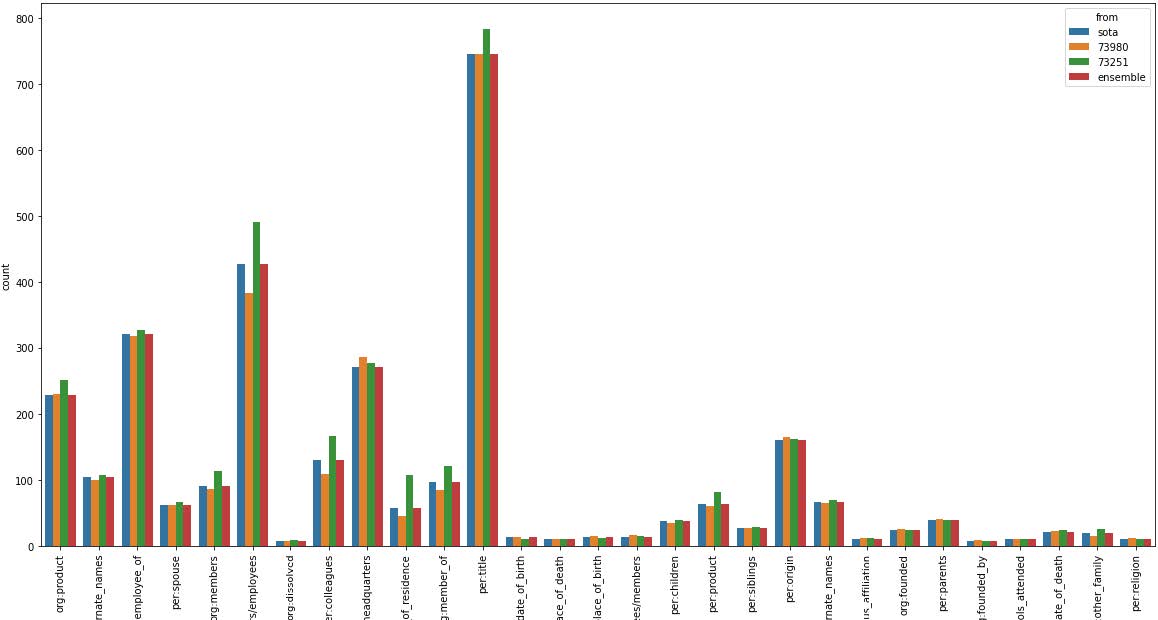
데이터는 위와 같이 매우 불균형하게 분포되어 있었고, 9,000개가 넘는 no_relation과 달리 per:place_of_death처럼 약 40개 정도만 존재하는 label도 있었습니다.
이렇게 극단적인 Data Imbalancing을 잘 잡는 것이 이번 대회의 핵심이라고 생각하게 되었습니다.

또한 sentence와 subject_entity, object_entity까지 전부 동일한 문장이 53개가 있는 등 중복된 데이터와 mislabeled 데이터들이 존재하였고, 이것들을 전부 제거하고 수정하여 데이터셋을 재구성하였습니다.
💪 Data Augmentation
이후에는 Data Imbalancing을 해결하기 위하여 여러 Augmentation 기법들로 실험을 이어나갔습니다.
EDA & AEDA
KoEDA 라이브러리를 사용하여 EDA, AEDA 각각 전체 데이터셋에 대해n_aug=[1, 2, 4]비율로 augmentation 진행- 두 방법 모두 아무것도 하지 않았을 때보다 validation score가 낮았음.
Undersampling & Oversampling
imblearn 라이브러리를 사용하여 SMOTE로 Sampling 진행
- 두 방법 모두 아무것도 하지 않았을 때보다 validation score가 낮았음.
Back Translation
Crawler를 사용하여 papago 번역기 사용.
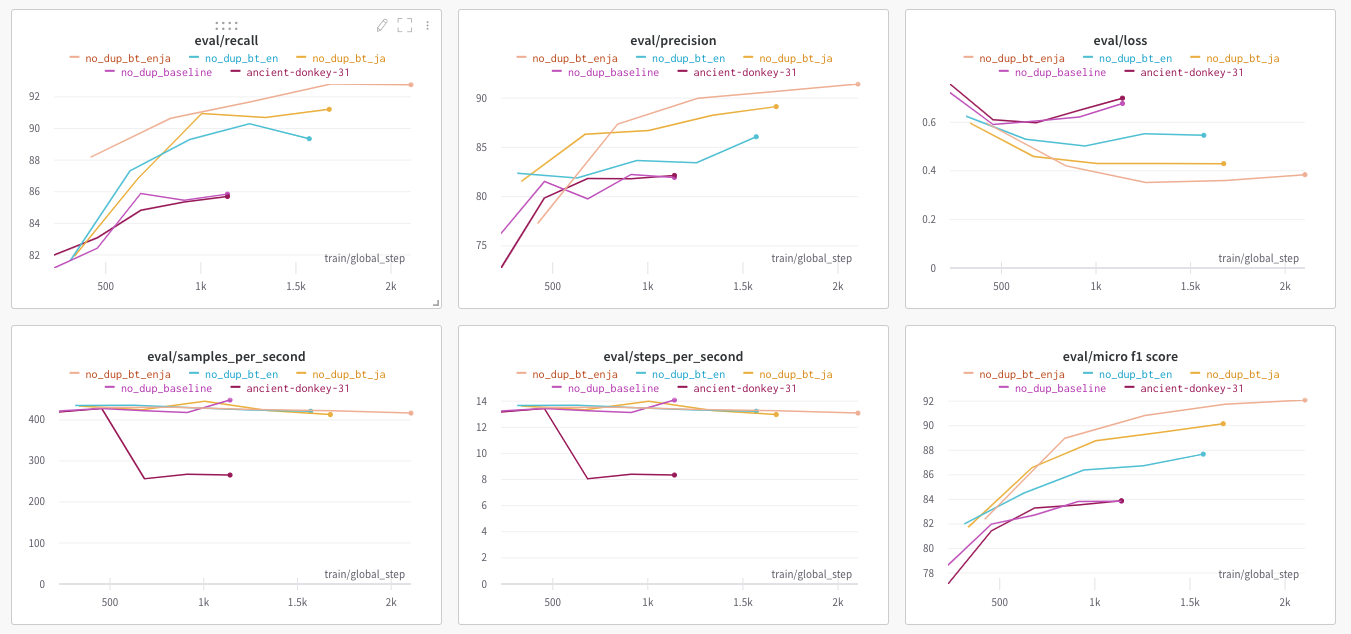
klue/roberta-small모델 기준으로 score 상승이 있었지만 너무 늦게 시도해서 best 모델에 적용하지 못했음.ko -> en -> ja -> ko: 약 0.1 LB Score 하락ko -> ja -> ko: 약 0.5 LB Score 상승
Target Augmentation subject <-> object label changing
kfold로 학습을 진행할 때 한 번이라도 틀린 data에 대해서 subject와 object entity를 변경함으로써 augmentation 진행- 약 0.05 LB Score 상승
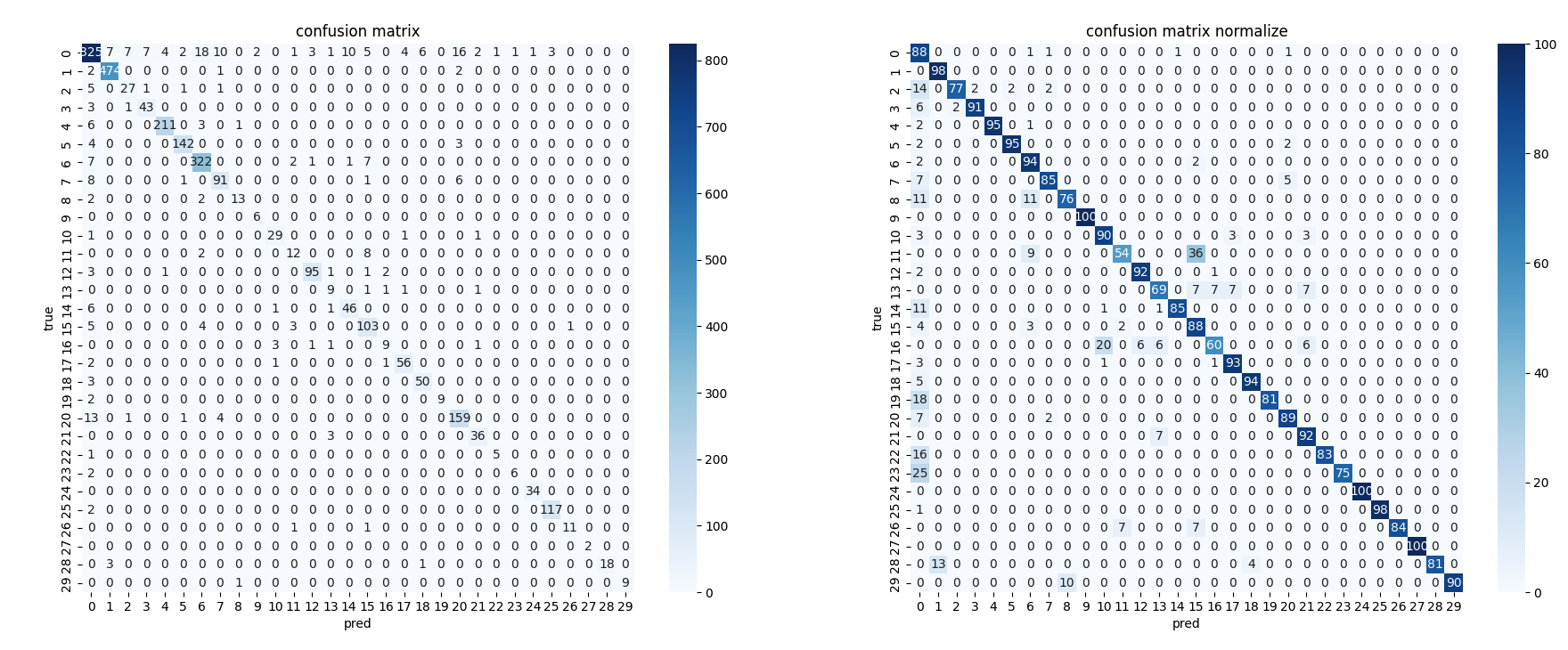
하지만 이러한 augmentation 기법들에 대해서 많은 효과를 볼 수가 없었는데, confusion matrix를 통해 원인을 유추해볼 수 있었습니다.
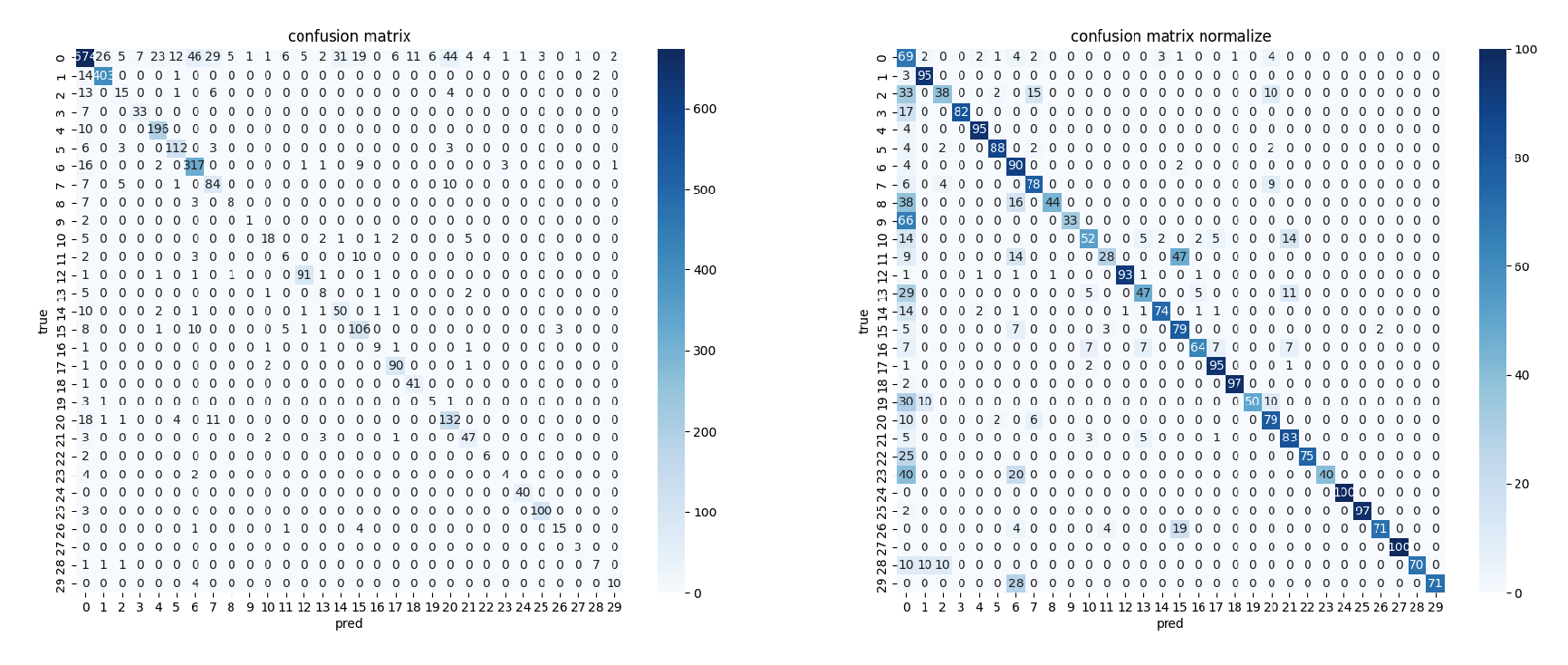
처음 예상과 다르게 적은 label의 데이터를 생각보다 잘 맞추고 있었고, 오히려 데이터 수가 가장 많았던 no_relation 예측에서 많이 틀리고 있었기 때문 이었습니다. 따라서 전체 데이터셋에 대해서 augmentation을 진행한 방식, 그리고 sampling 방식으로는 효과를 보지 못했다는 것을 알 수 있었습니다.
처음부터 이렇게 Confusion Matrix를 도입하여 현재 모델이 어떤 예측을 잘 수행하지 못하는지 등을 파악하여, no_relation에 대해서만 augmentation을 시도하는 등 디테일하게 augmentation 전략을 세웠으면 좋았을 것이란 아쉬움이 남습니다. 또한 4번 실험에서 sub <-> obj label만 변경하는 방식 말고 다른 augmentation 방법도 써봤으면 어땠을까 하는 아쉬움이 남습니다.
🔧 Data Preprocessing & Tokenizer
Dynamic Padding
Huggingface의 Tokenizer는max_length인자를 통해 기본적으로fixed padding방식을 사용합니다. 저희는 더 빠른 실험을 통해dynamic padding방식으로 변경하였고 그 결과 약 30%의 속도를 향상시킬 수 있었습니다.

An Improved Baseline for Sentence-level Relation Extraction
문장의 Subject, Object Entity의 NER Type을 명시해주고, Entity의 위치를 사전학습에서 사용된 특수문자를 이용하여 표기하는 Typed Entity Marker를 적용했습니다.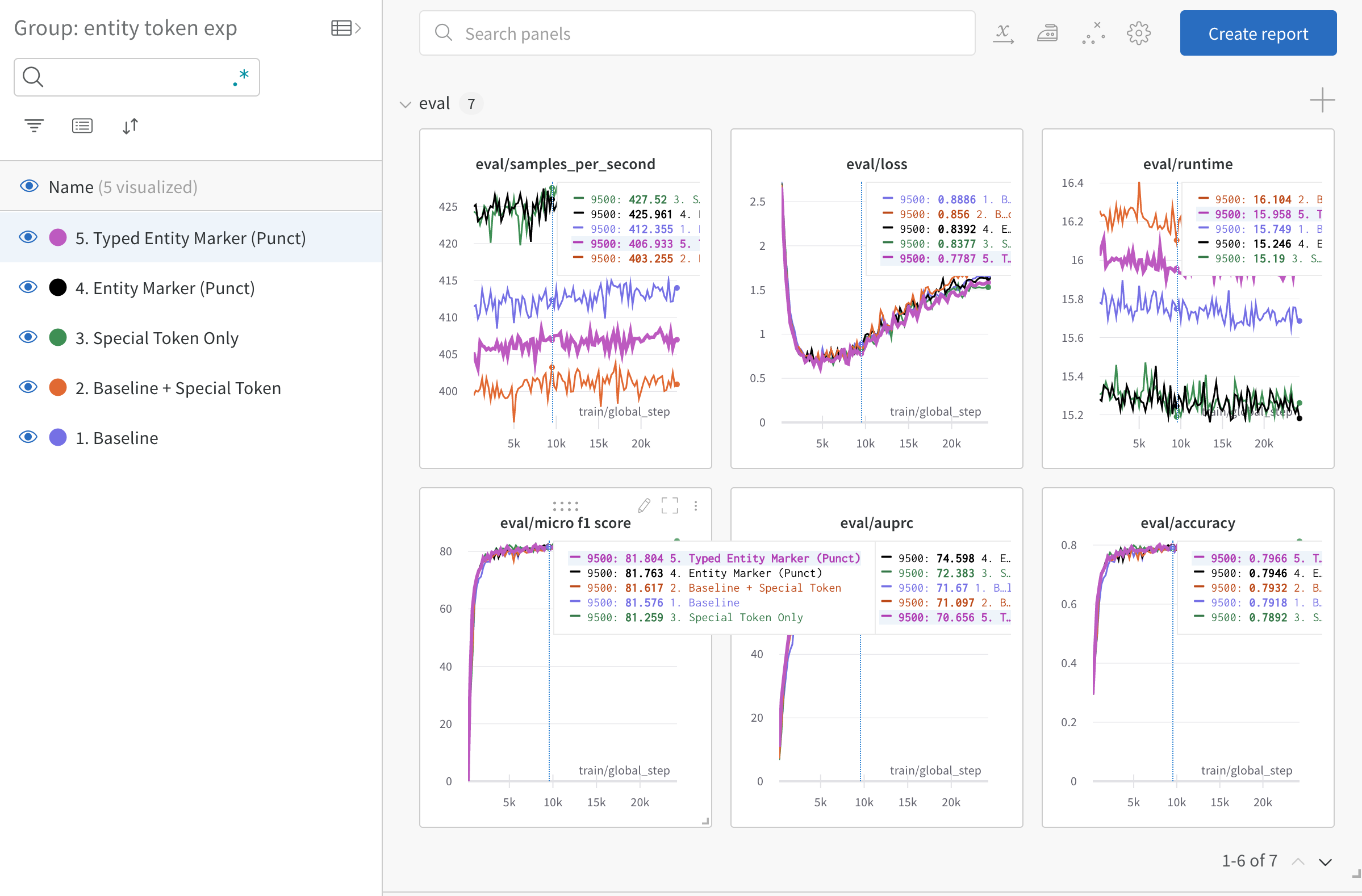
- vanilla : 기본 베이스라인 input
- special_ent :
기본 베이스라인 input + [sbj][sbj/] + [obj][obj/] - special_ent_without_prefix : 기본 베이스라인 input의 앞에있는
subject [sep] object [sep] 부분을 제거하고special token을 사용 (4, 5번 역시 prefix를 제거함) - punct_ent :
@sbj@ #obj#식으로 special token 없이 entity 표현 - punct_typing_ent :
@*sbj_type*sbj@ #^obj_type^obj#식으로 entity type을 알려주며 표현결과: 3번 5번이 비교적 가장 우수한 성능을 보임, 동일 조건 하 validation f1 기준 1 정도의 성능 차이를 보임.
위의 두 방법을 사용하여 실험과 검증은 조금 더 빠르게 진행할 수 있었고, 성능 향상을 이끌어낼 수 있었습니다.
🧘 Modeling
Backbone이 되는 Model은 klue/roberta-large를 사용하였으며 Base 성능은 avg. 71 (micro f1) 정도를 기록하였습니다.
여러가지 실험들
Entity Embedding
아무것도 하지 않았을 때보다 validation score가 낮았음.코드 보기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108class RobertaEmbeddingsWithTokenEmbedding(nn.Module):
'''
edit by 곽진성_T2011
'''
def __init__(self, model, config, pre_model_state_dict=None):
super().__init__()
self.word_embeddings = model.roberta.embeddings.word_embeddings
self.position_embeddings = model.roberta.embeddings.position_embeddings
self.token_type_embeddings = model.roberta.embeddings.token_type_embeddings
self.entity_embeddings = nn.Embedding(9, config.hidden_size, padding_idx=0)
if pre_model_state_dict:
pre_weight = pre_model_state_dict['roberta.embeddings.entity_embeddings.weight']
self.entity_embeddings.weight = torch.nn.parameter.Parameter(pre_weight, requires_grad=True)
self.LayerNorm = model.roberta.embeddings.LayerNorm
self.dropout = model.roberta.embeddings.dropout
self.position_embedding_type = getattr(config, "position_embedding_type", "absolute")
self.register_buffer("position_ids", torch.arange(config.max_position_embeddings).expand((1, -1)))
if version.parse(torch.__version__) > version.parse("1.6.0"):
self.register_buffer(
"token_type_ids",
torch.zeros(self.position_ids.size(), dtype=torch.long, device=self.position_ids.device),
persistent=False,
)
self.padding_idx = config.pad_token_id
def forward(
self, input_ids=None, token_type_ids=None, position_ids=None, inputs_embeds=None, past_key_values_length=0
):
if position_ids is None:
if input_ids is not None:
position_ids = self.create_position_ids_from_input_ids(input_ids, self.padding_idx, past_key_values_length)
else:
position_ids = self.create_position_ids_from_inputs_embeds(inputs_embeds)
if input_ids is not None:
input_shape = input_ids.size()
else:
input_shape = inputs_embeds.size()[:-1]
seq_length = input_shape[1]
if token_type_ids is None:
if hasattr(self, "token_type_ids"):
buffered_token_type_ids = self.token_type_ids[:, :seq_length]
buffered_token_type_ids_expanded = buffered_token_type_ids.expand(input_shape[0], seq_length)
token_type_ids = buffered_token_type_ids_expanded
else:
token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=self.position_ids.device)
if inputs_embeds is None:
inputs_embeds = self.word_embeddings(input_ids)
token_type_embeddings = self.token_type_embeddings(token_type_ids)
entity_ids = self.create_entity_ids_from_input_ids(input_ids)
entity_embeddings = self.entity_embeddings(entity_ids)
embeddings = inputs_embeds + token_type_embeddings
if self.position_embedding_type == "absolute":
position_embeddings = self.position_embeddings(position_ids)
embeddings += position_embeddings
embeddings += entity_embeddings
embeddings = self.LayerNorm(embeddings)
embeddings = self.dropout(embeddings)
return embeddings
def create_position_ids_from_inputs_embeds(self, inputs_embeds):
input_shape = inputs_embeds.size()[:-1]
sequence_length = input_shape[1]
position_ids = torch.arange(
self.padding_idx + 1, sequence_length + self.padding_idx + 1, dtype=torch.long, device=inputs_embeds.device
)
return position_ids.unsqueeze(0).expand(input_shape)
def create_entity_ids_from_input_ids(self, input_ids):
"""
map index 1~8 to the token that is related to sbj, obj entities
"""
s_ids = torch.nonzero((input_ids == 36)) # subject
o_ids = torch.nonzero((input_ids == 7)) # object
# entity type mapped into index 3 ~ 8
type_map = {4410 : 3, 7119 : 4, 3860 : 5, 5867 : 6, 12395 : 7, 9384 : 8}
entity_ids = torch.zeros_like(input_ids)
for i in range(len(s_ids)):
s_id = s_ids[i]
o_id = o_ids[i]
if i % 2 == 0:
entity_ids[s_id[0], s_id[1]+2] = type_map[input_ids[s_id[0], s_id[1]+2].item()]
entity_ids[o_id[0], o_id[1]+2] = type_map[input_ids[o_id[0], o_id[1]+2].item()]
else:
prev_s_id = s_ids[i-1]
prev_o_id = o_ids[i-1]
entity_ids[s_id[0], prev_s_id[1]+4:s_id[1]] = 1
entity_ids[o_id[0], prev_o_id[1]+4:o_id[1]] = 2
return entity_ids
def create_position_ids_from_input_ids(self, input_ids, padding_idx, past_key_values_length=0):
mask = input_ids.ne(padding_idx).int()
incremental_indices = (torch.cumsum(mask, dim=1).type_as(mask) + past_key_values_length) * mask
return incremental_indices.long() + padding_idxR-BERT
본 구조에서 BERT를 RoBERTa로 변경. LB 기준 71.362의 micro f1 score 달성.코드 보기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81class RBERT(RobertaPreTrainedModel):
'''
orgin code: https://github.com/monologg/R-BERT
edit by 문하겸_T2076
'''
def __init__(self, config, model_name):
super(RBERT, self).__init__(config)
self.roberta = RobertaModel.from_pretrained(
model_name) # Load pretrained bert
self.num_labels = config.num_labels
self.cls_fc_layer = FCLayer(
config.hidden_size, config.hidden_size, 0.1)
self.entity_fc_layer = FCLayer(
config.hidden_size, config.hidden_size, 0.1)
self.label_classifier = FCLayer(
config.hidden_size * 3,
config.num_labels,
0.1,
use_activation=False,
)
@staticmethod
def entity_average(hidden_output, e_mask):
"""
Average the entity hidden state vectors (H_i ~ H_j)
:param hidden_output: [batch_size, j-i+1, dim]
:param e_mask: [batch_size, max_seq_len]
e.g. e_mask[0] == [0, 0, 0, 1, 1, 1, 0, 0, ... 0]
:return: [batch_size, dim]
"""
e_mask_unsqueeze = e_mask.unsqueeze(1) # [b, 1, j-i+1]
length_tensor = (e_mask != 0).sum(
dim=1).unsqueeze(1) # [batch_size, 1]
# [b, 1, j-i+1] * [b, j-i+1, dim] = [b, 1, dim] -> [b, dim]
sum_vector = torch.bmm(e_mask_unsqueeze.float(),
hidden_output).squeeze(1)
avg_vector = sum_vector.float() / length_tensor.float() # broadcasting
return avg_vector
def forward(self, input_ids=None, attention_mask=None, token_type_ids=None, labels=None, e1_mask=None, e2_mask=None):
outputs = self.roberta(
input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids)
sequence_output = outputs[0]
pooled_output = outputs[1]
# Average
e1_h = self.entity_average(sequence_output, e1_mask)
e2_h = self.entity_average(sequence_output, e2_mask)
# Dropout -> tanh -> fc_layer (Share FC layer for e1 and e2)
pooled_output = self.cls_fc_layer(pooled_output)
e1_h = self.entity_fc_layer(e1_h)
e2_h = self.entity_fc_layer(e2_h)
# Concat -> fc_layer
concat_h = torch.cat([pooled_output, e1_h, e2_h], dim=-1)
logits = self.label_classifier(concat_h)
# add hidden states and attention if they are here
outputs = (logits,) + outputs[2:]
# Softmax
if labels is not None:
if self.num_labels == 1:
loss_fct = nn.MSELoss()
loss = loss_fct(logits.view(-1), labels.view(-1))
else:
loss_type = "focal"
beta = 0.9999
gamma = 2.0
loss_fct = CB_loss(beta=beta, gamma=gamma)
loss = loss_fct(logits.view(-1, self.num_labels),
labels.view(-1), loss_type)
outputs = (loss,) + outputs
return outputsModel split & combine
no_relation만 구분하도록 학습시킨 모델,relation만 구분하도록 학습시킨 모델,전체 데이터로 학습시킨 모델세 가지klue/roberta-large모델의 가중치를 freezing 하고 classifier만 학습시킨 것. LB 기준 73.251의 micro f1 score 달성.코드 보기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55class CombineModels(nn.Module):
'''
edit by 이요한_T2166
'''
def __init__(self):
super(CombineModels, self).__init__()
c1 = AutoConfig.from_pretrained('klue/roberta-large', num_labels=2)
c2 = AutoConfig.from_pretrained('klue/roberta-large', num_labels=29)
c3 = AutoConfig.from_pretrained('klue/roberta-large', num_labels=30)
self.roberta1 = AutoModelForSequenceClassification.from_pretrained(
"split_model_no_rel_large", config=c1)
self.roberta2 = AutoModelForSequenceClassification.from_pretrained(
"split_model_rel_large", config=c2)
self.roberta3 = AutoModelForSequenceClassification.from_pretrained(
"sota_kfold", config=c3)
for p in self.roberta1.parameters():
p.requires_grad = False
for p in self.roberta2.parameters():
p.requires_grad = False
for p in self.roberta3.parameters():
p.requires_grad = False
self.fc1 = nn.Linear(2, 768)
self.fc2 = nn.Linear(29, 768)
self.fc3 = nn.Linear(30, 768)
self.classifier = nn.Sequential(
nn.Dropout(p=0.1),
nn.Linear(768 * 15, 768, bias=True),
nn.Tanh(),
nn.Dropout(p=0.1),
nn.Linear(768, 30, bias=True)
)
def forward(self, input_ids, attention_mask):
logits_1 = self.roberta1(
input_ids.clone(), attention_mask=attention_mask).get('logits')
logits_2 = self.roberta2(
input_ids.clone(), attention_mask=attention_mask).get('logits')
logits_3 = self.roberta3(
input_ids.clone(), attention_mask=attention_mask).get('logits')
logits_1 = self.fc1(logits_1)
logits_2 = self.fc2(logits_2)
logits_3 = self.fc1(logits_3)
concatenated_vectors = torch.cat((
logits_1, logits_2, logits_3), dim=-1)
output = self.classifier(concatenated_vectors)
outputs = SequenceClassifierOutput(logits=output)
return outputsFC Layer -> LSTM
너무 늦게 도입하여 제출 실패.코드 보기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26class RobertaAddLSTM(RobertaPreTrainedModel):
'''
edit by 정희영_T2210
'''
def __init__(self, config, *args, **kwargs):
super().__init__(config=config)
self.bert = RobertaModel.from_pretrained("klue/roberta-large")
self.lstm = nn.LSTM(1024, 256, batch_first=True, bidirectional=True)
self.linear = nn.Linear(256*2, 30)
self.dropout = nn.Dropout(0.5)
self.tanh = nn.Tanh()
self.linear2 = nn.Linear(30, 1)
def forward(self, input_ids, attention_mask):
output = self.bert(input_ids, attention_mask=attention_mask)
lstm_output, (h,c) = self.lstm(output[0]) ## extract the 1st token's embeddings
hidden = torch.cat((lstm_output[:,-1, :256],lstm_output[:,0, 256:]),dim=-1)
linear_output = self.linear(hidden.view(-1,256*2))
x = self.tanh(linear_output)
x = self.dropout(x)
outputs = SequenceClassifierOutput(logits=x)
return outputsTAPT - Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks
주어진 학습데이터로 사전학습된 모델에 TAPT 를 적용해보았을 때 약 0.5 정도의 validation f1 score 향상이 있었으나, 시간문제로 논문에서 제안된 epochs만큼 학습을 진행하지 못했음. koelectra와 roberta-base로 리더보드에 제출해본 결과 큰 성능향상이 없었기 때문에 large 모델에 적용해볼 수 없었음.코드 보기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57'''
edit by 정진원_T2206
'''
from transformers import AutoTokenizer, RobertaForMaskedLM, ElectraForMaskedLM, BertForMaskedLM, AutoConfig, DataCollatorWithPadding, DataCollatorForLanguageModeling
import torch
from transformers import LineByLineTextDataset
from transformers import Trainer, TrainingArguments
from transformers import EarlyStoppingCallback
# fetch pretrained model for MaskedLM training
tokenizer = AutoTokenizer.from_pretrained('klue/roberta-large')
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = BertForMaskedLM.from_pretrained('klue/roberta-large')
model.to(device)
# Read txt file which is consisted of sentences from train.csv
dataset = LineByLineTextDataset(
tokenizer=tokenizer,
file_path='data/train.txt',
block_size=514 # block size needs to be modified to max_position_embeddings
)
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer, mlm=True, mlm_probability=0.2
)
# need to change arguments
training_args = TrainingArguments(
output_dir="./klue-roberta-retrained",
overwrite_output_dir=True,
learning_rate=5e-05,
num_train_epochs=200,
per_device_train_batch_size=16,
save_steps=100,
save_total_limit=2,
seed=30,
save_strategy='epoch',
gradient_accumulation_steps=8,
logging_steps=100,
evaluation_strategy='epoch',
resume_from_checkpoint=True,
fp16=True,
fp16_opt_level='O1',
load_best_model_at_end=True
)
trainer = Trainer(
model=model,
args=training_args,
data_collator=data_collator,
train_dataset=dataset,
eval_dataset=dataset,
callbacks = [EarlyStoppingCallback(early_stopping_patience=3)]
)
trainer.train()
trainer.save_model("./klue-roberta-retrained")
loss function
CB Loss
R-BERT를 제외하고는 큰 성능향상을 못봤음.코드 보기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72class MyTrainer(Trainer):
'''
edit by 문하겸_T2076
'''
def __init__(self, disable_wandb=True, *args, **kwargs):
super().__init__(*args, **kwargs)
self.disable_wandb = disable_wandb
def compute_loss(self, model, inputs, return_outputs=False):
labels = inputs.get("labels")
outputs = model(**inputs)
logits = outputs.get("logits")
beta = 0.9999
gamma = 2.0
criterion = CB_loss(beta, gamma)
if torch.cuda.is_available():
criterion.cuda()
loss_fct = criterion(logits, labels)
return (loss_fct, outputs) if return_outputs else loss_fct
def evaluation_loop(self, *args, **kwargs):
eval_loop_output = super().evaluation_loop(*args, **kwargs)
pred = eval_loop_output.predictions
label_ids = eval_loop_output.label_ids
self.draw_confusion_matrix(pred, label_ids)
return eval_loop_output
class CB_loss(nn.Module):
def __init__(self, beta, gamma, epsilon=0.1):
super(CB_loss, self).__init__()
self.beta = beta
self.gamma = gamma
self.epsilon = epsilon
def forward(self, logits, labels):
# self.epsilon = 0.1 #labelsmooth
beta = self.beta
gamma = self.gamma
no_of_classes = logits.shape[1]
samples_per_cls = torch.Tensor(
[sum(labels == i) for i in range(logits.shape[1])])
if torch.cuda.is_available():
samples_per_cls = samples_per_cls.cuda()
effective_num = 1.0 - torch.pow(beta, samples_per_cls)
weights = (1.0 - beta) / ((effective_num) + 1e-8)
weights = weights / torch.sum(weights) * no_of_classes
labels = labels.reshape(-1, 1)
weights = torch.tensor(weights.clone().detach()).float()
if torch.cuda.is_available():
weights = weights.cuda()
labels_one_hot = torch.zeros(
len(labels), no_of_classes).cuda().scatter_(1, labels, 1).cuda()
labels_one_hot = (1 - self.epsilon) * labels_one_hot + \
self.epsilon / no_of_classes
weights = weights.unsqueeze(0)
weights = weights.repeat(labels_one_hot.shape[0], 1) * labels_one_hot
weights = weights.sum(1)
weights = weights.unsqueeze(1)
weights = weights.repeat(1, no_of_classes)
cb_loss = focal_loss(labels_one_hot, logits, weights, gamma)
return cb_loss-
코드 보기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51class LDAMLossTrainer(Trainer):
'''
edit by 김민수_T2025
'''
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.n_per_labels = self.train_dataset.get_n_per_labels()
def compute_loss(self, model, inputs, return_outputs=False):
labels = inputs.get('labels')
outputs = model(**inputs)
logits = outputs.get('logits')
betas = [0, 0.99]
beta_idx = self.state.epoch >= 2
n_per_labels = self.n_per_labels
effective_num = 1.0 - np.power(betas[beta_idx], n_per_labels)
cls_weights = (1.0 - betas[beta_idx]) / np.array(effective_num)
cls_weights = cls_weights / np.sum(cls_weights) * len(n_per_labels)
cls_weights = torch.FloatTensor(cls_weights)
criterion = LDAMLoss(cls_num_list=n_per_labels, max_m=0.5, s=30, weight=cls_weights)
if torch.cuda.is_available():
criterion.cuda()
loss_fct = criterion(logits, labels)
return (loss_fct, outputs) if return_outputs else loss_fct
class LDAMLoss(nn.Module):
def __init__(self, cls_num_list, max_m=0.5, weight=None, s=30):
super().__init__()
m_list = 1.0 / np.sqrt(np.sqrt(cls_num_list))
m_list = m_list * (max_m / np.max(m_list))
m_list = torch.cuda.FloatTensor(m_list)
self.m_list = m_list
assert s > 0
self.s = s
self.weight = weight
def forward(self, x, target):
index = torch.zeros_like(x, dtype=torch.bool)
index.scatter_(1, target.data.view(-1, 1), 1)
index_float = index.type(torch.cuda.FloatTensor)
batch_m = torch.matmul(self.m_list[None, :], index_float.transpose(0, 1))
batch_m = batch_m.view((-1, 1))
x_m = x - batch_m
output = torch.where(index, x_m, x)
return F.cross_entropy(self.s * output.to('cuda'), target.to('cuda'), weight=self.weight.to('cuda'))
결과적으론 backbone 모델의 kfold score를 넘어서지 못했습니다. 그 이유로는 public leaderboard와 간극이 적은 적절한 validation dataset을 구성하지 못했기 때문입니다.
차선책으로 미리 stratified하게 0.1 비율로 split한 train, validation dataset을 고정시켜놓고 사용하였지만, 해당 데이터셋의 validation score는 public leaderboard와 평균적으로 15점 이상, 극단적인 경우 30점까지 차이가 존재 했습니다. 이러한 validation dataset으로만 실험을 했기 때문에 validation score를 신뢰하기 어려웠고, model이 좋은지 나쁜지 직접 제출해보기 전에는 알 수 없었습니다.
따라서 제출횟수가 한정적이므로 대부분 위의 validation score로만 검증을 했고, 성능향상 가능성이 없다고 판단해 추가적인 실험을 진행하지 못했습니다. 하지만 막상 1, 2등의 solution을 보니 저희가 진행했던 실험들로 점수를 올렸기에 속이 쓰렸습니다… :(
다음 대회에서는 public leaderboard와의 간극이 적은 적절한 validation dataset을 구성할 필요가 있으며, 또한 교차검증을 위한 validation dataset 역시 고정시켜놓을 필요가 있다고 느꼈습니다.
🍜 Ensemble
K-fold
klue/roberta-large모델을 사용하여 kfold(k=5)를 사용하여 성능을 개선하였습니다. single fold 기준 public leaderboard에서 약 71의 micro f1 score를 기록하였고, 5 fold ensemble을 통해 public leaderboard에서 73.5의 micro f1 score를 기록할 수 있었습니다.
👨🎨 앙상블 깎는 노인과 기도메타
저희는 public leaderboard 기준 73 정도의 micro f1 score를 기록하였지만 예측 분포가 다른 결과들을 soft voting하여 public leaderboard 기준 74.306의 micro f1 score를 기록할 수 있었습니다.





최종적으로 제출된 결과는 Ensemble된 것들 중 public leaderboard 기준 AUPRC가 가장 높은 결과이며, private leaderboard 에서 다른 팀 대비 점수 하락폭이 적어서 순위가 9등 -> 5등으로 상승했습니다.
결과적으로 모델링 실험에서 압도적인 성능 향상을 이루진 못했지만, 비슷한 점수의 다른 분포를 가지는 결과들을 많이 만들어놓았던 것이 앙상블에서 더욱 일반화된 결과를 얻을 수 있었던 요인이었다고 생각합니다.
💯 Good Practice
저희 팀만의 Good Practice는 체계적으로 Notion에 실험관리를 한 것도 있지만, huggingface의 다양한 기능들을 사용해봤다는 것이고 그 중에서 좋은 효과를 낸 것으로는 fp16과 hyperparameter_search가 있습니다.
fp16
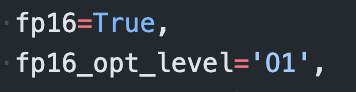
fp16은Mixed-Precision Training으로 32-bit Floating Point가 아닌 16-bit Floating Point를 사용하는 방식입니다. 이 방식을 통해 모델을 학습시킬 때 성능은 비슷하지만 약 60% 가량의 향상된 속도로 학습을 진행할 수 있었습니다.
TrainingArguments에fp16=True,fp16_opt_level='O1'만 추가하면 바로 사용할 수 있어서 간단하게 다양한 실험을 진행할 수 있었습니다.
hyperparameter_search
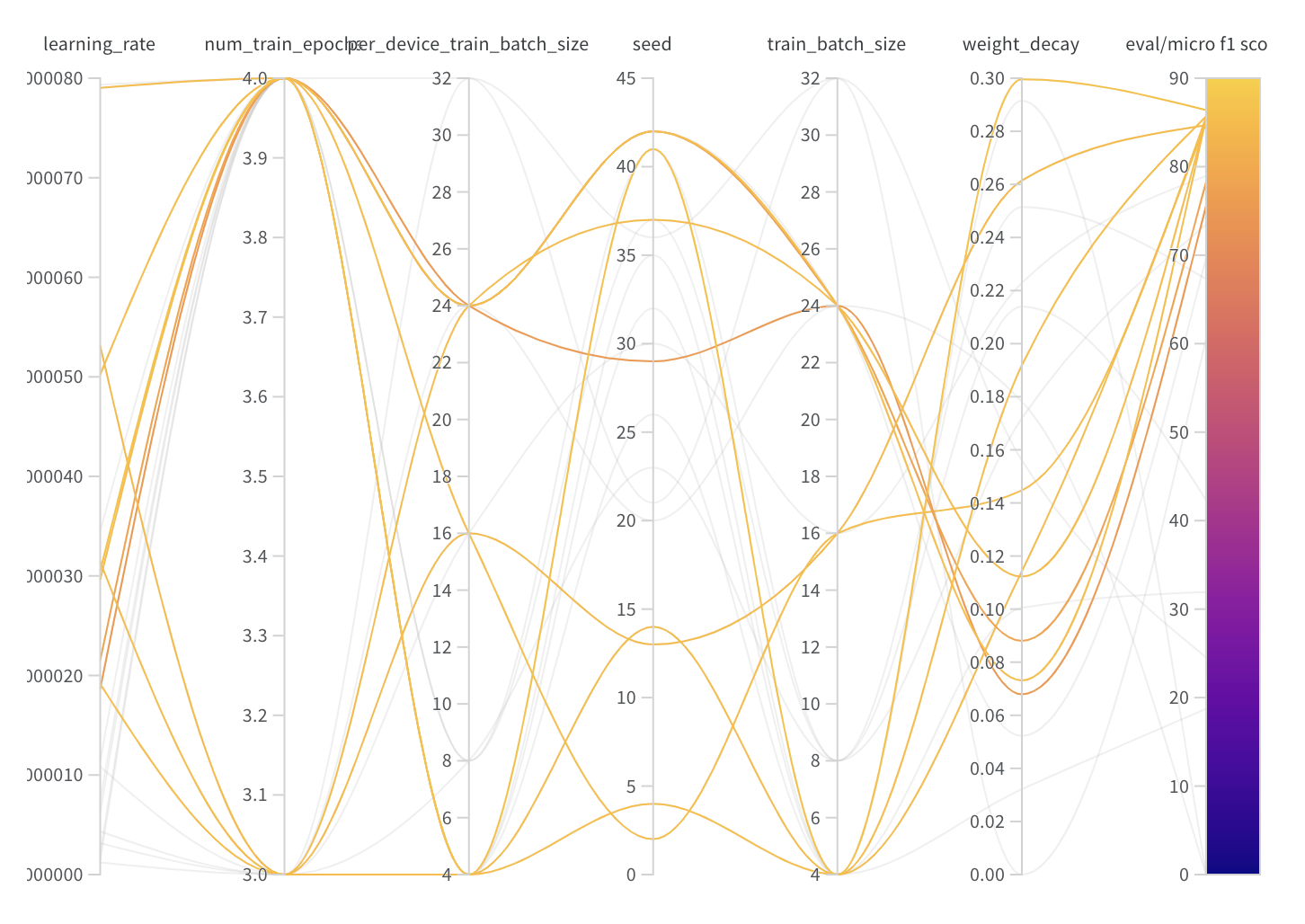
hyperparameter_search는Trainer에 존재하는 method로raytune,optuna,SigOpt세 가지 중 자신의 환경에 설치되어 있는 라이브러리를 이용하여 적절한 hyperparameter를 탐색해주는 유용한 함수입니다. 저희는hyperparameter_search로 public leaderboard 기준 4점 이상의 f1 score 향상을 기록할 수 있었습니다.코드 보기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45from transformers import AutoModelForSequenceClassification, AutoConfig, AutoTokenizer, Trainer, TrainingArguments
# TODO: load your tokenizer & dataset
# tokenizer = ...
# dataset = ...
# TODO: change your pretrained model path
config = AutoConfig.from_pretrained("YOUR_MODEL_PATH")
def model_init():
return AutoModelForSequenceClassification.from_pretrained(
model_path, config=config)
# TODO: fill it your training arguments
training_args = TrainingArguments(...)
# TODO: fill it your trainer arguments
trainer = Trainer(
model_init=model_init, # NOTE: 반드시 model_init 함수로 모델을 불러와야합니다.
args=training_args,
...
)
# NOTE: optuna
def optuna_hp_space(trial):
return {
"learning_rate": trial.suggest_float("learning_rate", 5e-6, 5e-4, log=True),
"num_train_epochs": trial.suggest_int("num_train_epochs", 1, 5),
"seed": trial.suggest_int("seed", 1, 42),
}
# NOTE: ray tune
def ray_hp_space():
from ray import tune
return {
"learning_rate": tune.loguniform(5e-6, 5e-4),
"num_train_epochs": tune.choice(range(1, 6)),
"seed": tune.choice(range(1, 42)),
}
trainer.hyperparameter_search(
direction="maximize", # NOTE: or direction="minimize"
hp_space=ray_hp_space, # NOTE: if you wanna use optuna, change it to optuna_hp_space
backend="ray", # NOTE: if you wanna use optuna, remove this argument
)
또한 W&B를 팀으로 만들어서 팀원들이 실험하는 결과들을 전부 공유할 수 있게 만들었습니다. 덕분에 실패한 실험이나 성공한 실험들에 대해서 chart를 통해 더욱 쉽고 직관적으로 모델을 검증할 수 있었고, 팀원간 더 빠른 결과 공유가 가능했습니다.
💌 Thanks to
청계산셰르파의 비밀병기, 이유경 멘토님.
정말 바쁘신 와중에도 많은 것을 알려주시려고 열심히 찾아보시고, 따로 공부도 해가시면서 저희에게 많은 도움을 주셨습니다. 저희의 등반일지에 가장 큰 기여를 하신 이유경 멘토님께 다시한번 감사의 말씀 전해드리고 싶습니다.
청계산셰르파 팀명에 항상 불만을 가지시는 성예닮 멘토님
유경멘토님의 사생팬답게 저희팀에도 많은 관심가져주시고 지켜봐주셔서 정말 든든합니다. 항상 말씀못드리는게 죄송할정도로, 많은 도움 주시고 알려주셔서 정말 감사합니다.
마지막으로
저희가 처음에 계획했던 기록과 공유라는 가치에 있어서만큼은 전반적으로 팀원 모두가 만족할 수 있었던 프로젝트였습니다.
처음 합을 맞춤에도 불구하고 팀원 모두가 다음 프로젝트에서는 어떠한 역할을 수행하고, 어떤 식으로 협업을 하는 것이 효과적일지 스스로 깨우칠 수 있었다는 점에서 굉장히 고무적이며, 많은 깨달음을 얻을 수 있었던 경험이었습니다.
너무 좋은 팀원분들과 함께할 수 있어서 정말 좋았고 다음 대회가 너무나도 기다려지네요.
저희의 이야기가 조금이라도 도움이 되었길 바라면서 마치겠습니다.
긴 글 읽어주셔서 감사합니다.
🤜 부록: 팀원들 한마디
좋았던 점
- 요한: 철저하게 기록을 하고, 실험결과를 공유했던 점이 가장 잘 한 것 같습니다. 특히 다양한 협업툴을 두고 사용한 것보다 그 기능들을 노션에다가 전부 통합하여 사용한게 혼란이 적어 잘 된 것 같습니다.
- 하겸: 실험 자체를 다양하게 시도하고, 실험 공유가 잘 됬던 것 같습니다. 이전 실험의 결론에서 다음 실험은 어떻게 할지를 정한 것도 좋았습니다.
- 준영: 팀원 간에 공유가 잘되서 좋았습니다. 기록이 잘되다보니 제가 하지 않은 실험에서도 아이디어를 가져올 수 있었습니다.
- 진원: 팀원들끼리 결과 공유와 기록이 잘 이루어졌습니다. 열심히 한 만큼 최종적으로도 괜찮은 결과를 얻어서 만족합니다.
- 민수: 실험을 많이 했던 것. 제출 횟수를 꽉 채워서 쓴게 좋았습니다.
- 희영: 의견 공유가 잘 되어서 내가 하지 않은 실험에서도 지식을 얻을 수 있어서 좋았습니다. 팀원들과 멘토님이 지식이 많아서 진짜 빠르게 배웠습니다.
- 진성 : 각자 실험에 있어 통제변인 설정을 철저히 하고 기록을 세세하게 해, 실험의 효과를 공유하기 좋았습니다.
아쉬운 점
- 요한: 여러 실험 아이디어들이 있었지만, 막판으로 갈 수록 성능에 집착하여 큰 모델로만 실험을 하느라 모든 아이디어들에 대해서 실험을 하지 못했던 것이 아쉽습니다.
- 하겸 : 간극이 적은 validation set을 결국은 못찾았다. → 어떻게 찾을 수 있을지는 아직도 모르겠습니다. 성능면에서도 큰 도움이 되지 않아서 아쉬웠습니다.
- 준영: 모델 작업을 하지 못했습니다. 데이터 관련해서 많은 인사이트를 찾아보고 싶었지만 결과를 제대로 내지 못했습니다.
- 진원: 모델을 수정하는 작업을 많이 하지 못해 아쉬웠습니다. 다양한 실험을 진행하였지만, 모델의 성능을 올리는데 크게 기여하지 못했습니다.
- 민수: 모델을 태스크에 맞게 보다 적극적으로 변형하려는 시도를 하지 않았습니다.
- 희영: 대회 초기 생활 스케줄이 꼬여서 시간 낭비를 많이 했습니다. 생활 습관을 잘 잡고 시작하는 게 중요할 것 같습니다.
- 진성 : 수동적으로 할 일을 받아서 하거나, 다른 사람의 branch에 덧붙여서 작은 실험들만 했습니다. 다음 대회에서는 나도 적극적으로 논문 등에서 아이디어를 얻어와 큼직하게(빠르게) 정확하게 구현하는 연습을 해보자.
개선할 점
- 요한: 성능은 어차피 오를 것이기 때문에, 비슷한 실험을 여러번 하는 것보다는 떠올린 아이디어들에 대해 전부 실험할 수 있도록 해봐야겠습니다.
- 하겸: 일단 강의부터 들어서 맨땅에 헤딩하지 않기
- 준영: 강의 빠르게 듣기. 데이터 빠르게 훑어보기. 모델 뜯어보기.
- 진원: 모델을 수정해보는 실험을 진행하고, 확실하게 성능 향상을 이루기 위해 실험을 진행할 때 조금 더 명확한 근거나 방법을 미리 조사해보고 진행하면 좋을 것 같습니다 (e.g. 논문 읽어서 train 횟수 정하기).
- 민수: 어떤식의 변형이 해당 태스크에 적합한지 단순 점수와 느낌 이외에 정량적으로 검증할 수 있는 방법론을 생각해보면 좋을 것 같습니다.
- 희영: 첫날 진짜 빠르게 강의 다 듣기. 10시~12시 사이 시간 잘 이용하기. 이동 후 바로 시작하기, 12시 넘으면 집에서 공부할 생각하지 말기. EDA를 너무 오래 하고 raw 데이터를 너무 많이 보면 시간 낭비일수도.
- 진성 : 후반부에 기록을 하는 데에 신경을 많이 못썼습니다. 결국 남는건 기록이니 다음 대회 긴 기간동안에도 꾸준히 기록하자.