KLUE-RE NLP 왕초보 후기(문하겸)
P-stage (KLUE-RE) NLP 왕초보 후기(하겸)
글을 쓰기에 앞서
- 저는 NLP에 어렴풋한 관심은 있었지만 그렇다고 NLP는 나의 인생을 걸만한 목표야! 까지는 않았던 사람입니다. 대충 어떤 모델, 방법론이 있다 정도만 알고 있는 수준이었죠.
- 하지만 공부를 할 때 그냥 눈으로만 개념을 익히면 완전히 자신의 것이 되지 않는 것은 모두 알고 있는 사실일 겁니다. 하다못해 게임만 하더라도 유튜브에서 고수들의 영상을 보는 것으로 자기가 그와 비슷한 고수가 되지는 않죠. 직접 연습, 플레이해야 자신의 것이 되는 것이겠죠.
- 저에게 이번 P-stage가 그랬습니다. 어렴풋이 알고 있는 것들을 직접 코딩하고, 모델링을 해보면서 조금은 뚜렷하게 받아들여진 것 같습니다.
- 이번 회고는 거의 아무것도 모르던 왕초보가 P-stage를 겪으면서 어떻게 초보가 되어 갔는지에 대한 기록입니다.
1. 어떤 대회 인가요? KLUE는 뭐고 RE는 뭐죠?🤔
1.1 KLUE
- 한국 사람이 NLP를 시작했다면 KLUE란 단어를 어디선가 들어 봤을 겁니다. 저도 그랬고요. 하지만 정확히 KLUE가 뭔지는 몰랐죠. 그냥 MNIST 같은 건가? 라고 어렴풋이 생각했을 뿐입니다.


처음 KLUE를 들었을 때의 내 심정…. 그래서 KLUE가 뭔데!!!!!
- KLUE가 뭔지 알려면 먼저 GLUE를 알아야합니다.
- GLUE : General Language Understanding Evaluation의 약자로 UW, NYU, DeepMind 등이 모여 협업한 벤치마크 데이터 세트입니다. 자연어 이해를 평가할 수 있는 11개의 과제들로 구성되어 있습니다. 다양한 언어 모델이 통일된 일련의 데이터 세트 안에서 평가될 수 있었고, 모델 간의 공정한 비교를 통해 언어 모델이 빠른 속도로 발전할 수 있는 원동력이 되었습니다.
- 그렇다면 GLUE는 모든 언어 모델의 벤치마크를 할 수 있나요?
- GLUE가 공신력이 있고 논문에서도 종종 등장 하지만 영어로 이루어진 데이터 세트기 때문에 다른 언어에 대한 성능을 평가하는 것에는 어려움이 있었고 비 영어권 국가(프랑스, 중국, 러시아, 인도, 인도네시아 등)에서 벤치마크 데이터 세트가 공개 되었습니다.
- 한국어 자연어처리 분야에도 사전학습된 다양한 언어모델이 공개되고 활용되고 있었지만, 그 모델들을 공신력 있게 평가 할 수 있는 벤치 마크가 없었습니다. 기존에 제작된 한국어 데이터 세트들을 벤치마크로 활용하기 어려웠을 뿐 아니라 벤치마크 제작을 위해 다양한 기관의 협업을 이끌어 내기 어려웠기 때문입니다.
- 그래서 KLUE가 등장했습니다.
- 한국어 언어 모델이 구문록적, 의미론적 표상을 제대로 학습했는지 평가 할 수 있는 과제를 포함하고, 학계뿐 아니라 산업계에서도 수요가 있는 과제를 포함하는 한국어 벤치마크 데이터 세트… 그것이 KLUE 입니다.
- KLUE는 다음과 같은 Task를 포함합니다.
- 개체명 인식(Named Entity Recognition)
- 의존 구문 분석(Dependency Parsing)
- 문장 분류(Text classification)
- 자연어 추론(Natural Language Inference)
- 문장 유사도(Semantic Textual Similarity)
- 관계 추출(Relation Extraction)
- 질의 응답(Question & Answering)
- 목적형 대화(Task-oriented Dialogue)
- 일상 대화 이해(Open-domain Dialogue Understanding)
1.2 RE
- 위에서 KLUE Task의 6번 관계 추출(Relation Extraction)의 약자가 RE입니다. 관계 추출이라… 어떤 것을 의미할까요?
- 관계 추출(Relation Extraction)은 문장의 단어(Entity)에 대한 속성과 관계를 예측하는 문제입니다. 관계 추출은 지식 그래프 구축을 위한 핵심 구성 요소로, 구조화된 검색, 감정 분석, 질문 답변하기, 요약과 같은 자연어처리 응용 프로그램에서 중요합니다. 비구조적인 자연어 문장에서 구조적인 triple을 추출해 정보를 요약하고, 중요한 성분을 핵심적으로 파악할 수 있습니다.
- 이렇게 봐서는 살짝 이해가 가지 않습니다. input data는 무엇이고 어떤 결과를 도출해 내면 되는지 확인해 보겠습니다.
1 | |
- 즉 문장에 포함된 subject entity와 object entity의 관계를 도출해 내는 Task라고 이해 할 수 있습니다. 다만 한가지 기억해야 할 것은 같은 문장이더라도 subject entity와 object entity가 다르게 주어진다면 모델의 output 역시 달라져야 할 것입니다.
1.3 P-stage 개요
단순하게 RE Task를 잘 수행하는 모델을 만들어 제출해라! 라고 말하면 아쉬우니 대회의 룰과 데이터의 통계를 살펴보겠습니다.
전체 데이터에 대한 통계는 다음과 같습니다.
- train.csv: 총 32470개
- test_data.csv: 총 7765개 (정답 라벨 blind = 100으로 임의 표현)
- 학습을 위한 데이터는 총 32470개 이며, 7765개의 test 데이터를 통해 리더보드 순위를 갱신합니다. public과 private 2가지 종류의 리더보드가 운영됩니다.
- Data 예시

column 1: 샘플 순서 id
column 2: sentence.
column 3: subject_entity
column 4: object_entity
column 5: label
column 6: 샘플 출처
Class 설명
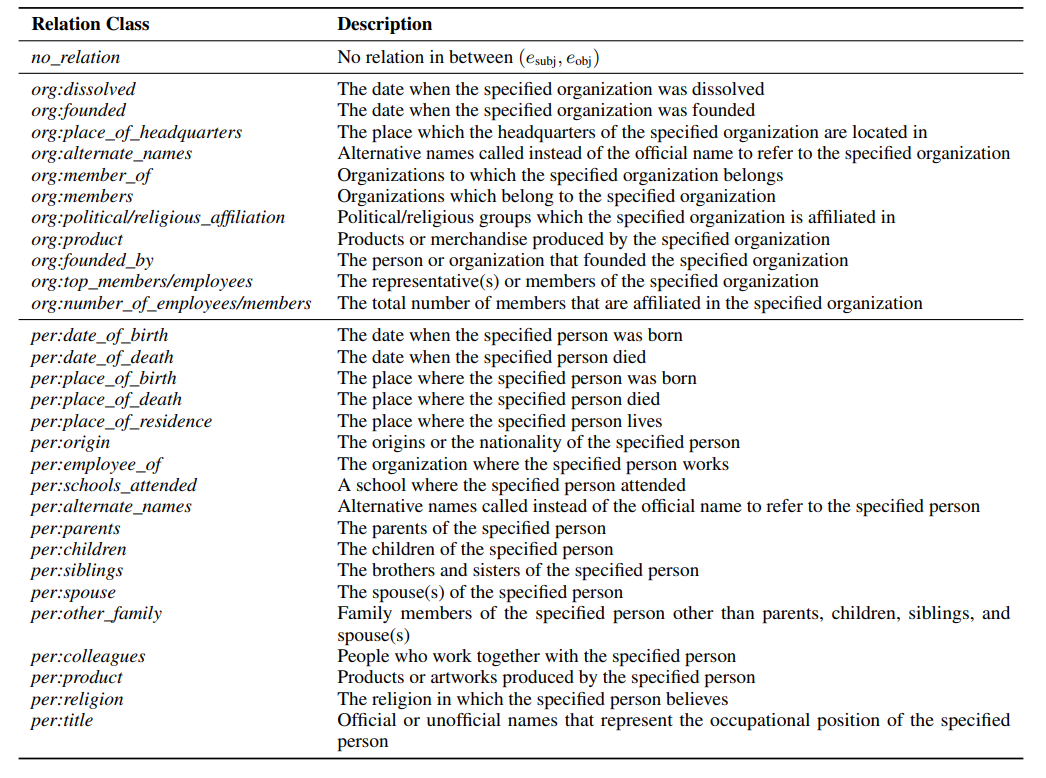
대회 참여 규칙
[외부 데이터셋 규정] 외부 데이터 사용은 금지합니다. 학습에 사용될 수 있는 데이터는 AI Stages 에서 제공되는 데이터셋 한 가지 입니다.
[평가 데이터 활용] test_data.csv에 대한 Pseudo labeling을 금지합니다. test_data.csv을 이용한 TAPT(Task-Adaptive Pretraining)는 허용 합니다. 단 평가 데이터를 눈으로 직접 판별 후 라벨링 하는 행위는 금지합니다. 제공된 학습 데이터을 사용한 데이터 augumentation 기법이나, 생성모델을 활용한 데이터 생성 등, 학습 데이터를 활용한 행위는 허용 됩니다.
(학습 효율 측면에서 테스트셋의 라벨링을 추론하는 행위는 본 대회에서는 금지합니다)
2. 어떤 방식으로 문제(P-stage)를 해결 하려고 했나요? 🧭
2.1 기록의 기록에 의한 기록을 위한…
저희 팀 청계산 셰르파는 P-stage competition에서 1등을 하기보다는 부스트 캠프에서 공부, 시도, 도전 그 결과 여부에 상관없이 모든 것을 생생하게 기록으로 남기는 것을 목표로 모인 팀입니다. NLP를 잘하는 사람들이 모인 것이 아니라 기록과 그것을 공유하는 것을 가장 중요하게 여기는 캠퍼들이 모인 팀입니다. 굳이 따지면 NLP 실력 자체는 특출나게 뛰어나지는 않았습니다.
닐 암스트롱의 발자국이 아직도 달에 남아 있습니다. 그 발자국처럼 저희도 오랫동안 지워지지 않을 기록을 위해 모인 것이죠. 이렇게 제출용 회고록 말고 따로 회고를 남기는 것도 그것을 위함입니다.
그렇기에 저희는 이번 P-stage에서 모든 것을 기록하기로 했습니다. 물론 모든 것을 다 할 수는 없지만 적어도 최대한 기록하려고 했습니다. 실험, 시도, 성공, 실패 그리고 그 모든 것을 함께 공유하기로 했습니다.
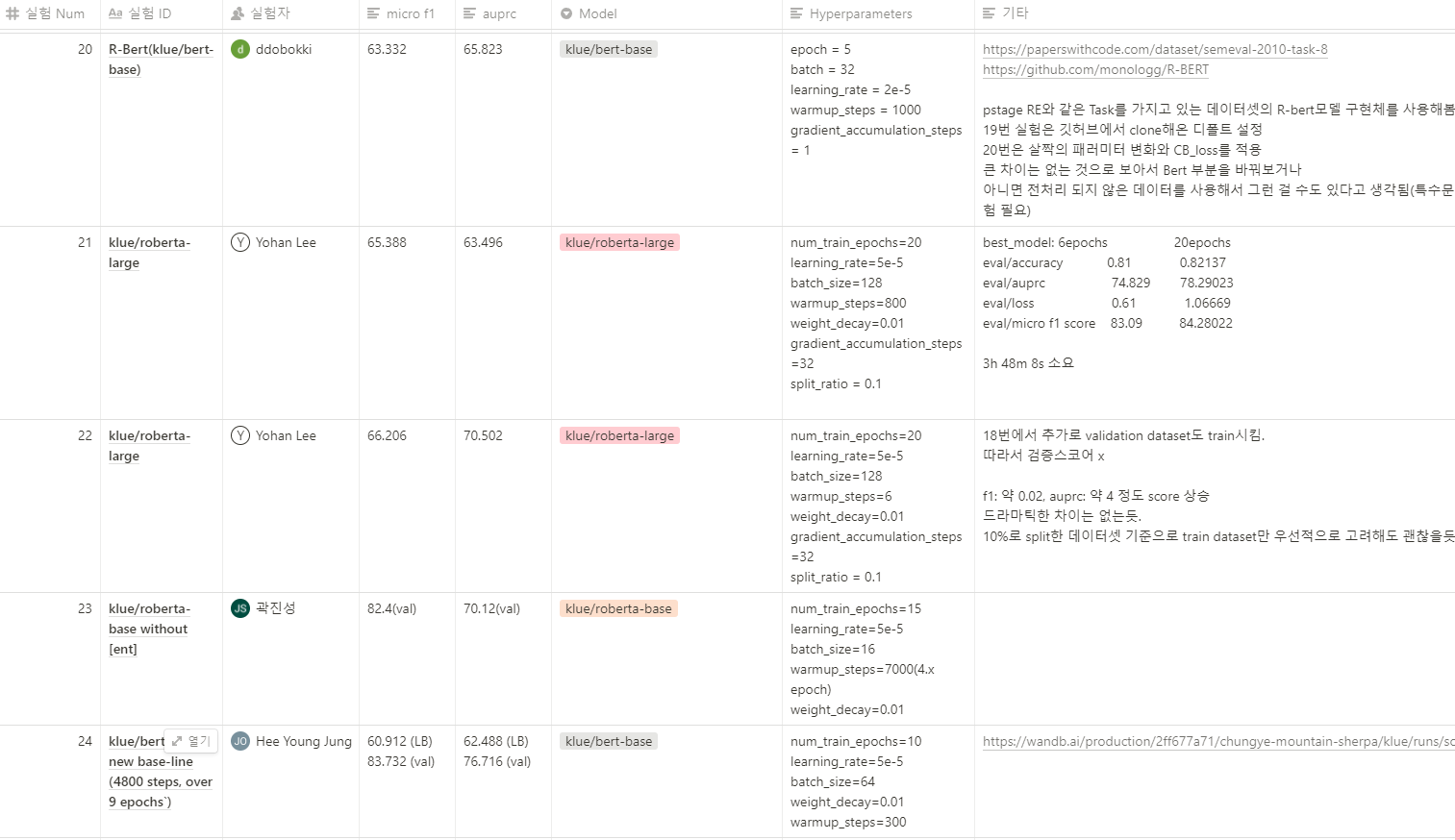
이렇게 모델, 패러미터, 점수, 간단한 고찰만 기록하는 것이 아니라
개인의 연구일지를 통해
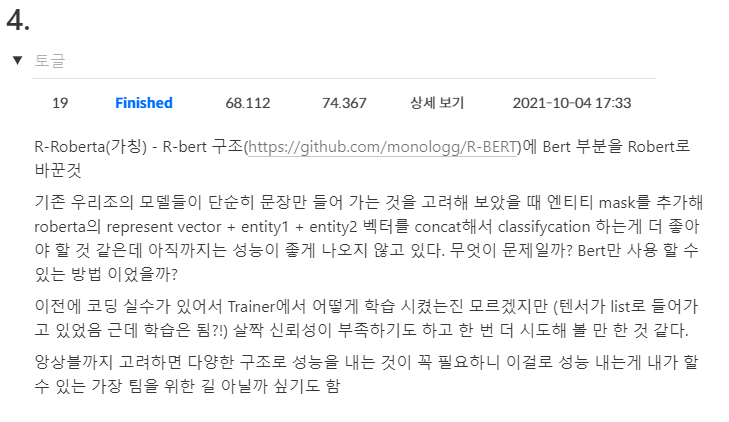
왜 그런 실험을 했고, 결과와 앞으로 어떤 실험을 진행할 것인지 간단하게라도 적었습니다.
- 물론 위에 언급한 기록 말고도 Kanban을 통한 실험 계획, 회의록, 멘토링, 유용한 자료, 논문, github 주소 등등 기록 할 수 있는 모든 것을 기록했습니다.
- TMI로 이렇게 기록해두니 모델의 개선 같은 실용적인 부분뿐만 아니라 연구 일지에서 개개인의 스타일이 달라서 구경하는 재미가 쏠쏠했습니다. 👍
2.2 객체지향?! 기록지향!! 실험지향!!
위에서 언급한 것처럼 저희 팀은 기록과 공유가 1 옵션이었습니다. 그 결과 개인의 실험을 상세하게 기록할 수 있었고, 중복되는 실험이 없었으며, 효과가 있었던 방법 들을 그때그때 바로 적용 할 수 있었고, 별로였던 시도를 다른 인원이 다시 실험하지 않게 돼서 정말 다양한 실험을 할 수 있었던 것 같습니다.
저 시도 하나하나가 중복이나 헛된 시도가 거의 없었습니다.
아래에서 언급 하겠지만 저희 조는 5등이라는 꽤 좋은 결과를 얻었습니다. 위에서 말한 것처럼 NLP 실력이 특출나지 않은, 어찌 보면 NLP 초보들이 모인 팀에서 이런 결과를 얻을 수 있었던 것은 기록을 철저하게 한 것, 공유를 활발히 한 덕분이라고 생각합니다.

「기록의 차이」가 느껴지십니까?
2.3 기록과 공유가 1순위면 등수는 아예 신경을 쓰지 않았나요?!🙄

그게 아니죠~!
- 여러 부자들이 돈 자체가 인생의 목적이어서 부자가 된 게 아니고 좋아하는 일, 의미 있는 일을 하다 보니 돈은 알아서 따라 들어왔다고 말을 합니다. 이와 비슷한 맥락으로 저희는 기본을 탄탄히, 차근차근히 하면 등수는 알아서 따라오리라 생각했습니다. 실제로도 그랬습니다.
- 기본을 탄탄히 한다는 것이 어떤 뜻일까요? 실험을 하면 변인 통제를 확실히 하고, 그 결과를 기록및 공유하며 그 결과에 따라 다음 실험 및 시도를 논리적으로 선택하는 것이 아닐까요? 결국 기록과 공유입니다.
- 즉 등수를 아예 신경 쓰지 않았다기보다는 조금은 귀찮고 힘들 수 있어도 기록을 꼼꼼히, 그리고 그것을 확실히 공유하면 당연히 따라 들어오는 상 정도로 받아들이기로 했습니다. 만약 기록과 공유를 철저히 했음에도 불구하고 하위권 점수를 얻었으면 저희 조의 컨셉을 바꾸게 됐을 지도 모르지만(가능성은 작지만) 결국 올바른 선택이었음이 판명되었습니다.
3. 등반일지 🏔
등반일지는 약 2주일가량 펼쳐진 P-stage의 저희 팀의 실험을 정말 간략하게만 써보겠습니다. 모든 시도를 적기에는 너무 늘어지는 감이 있으니 대략적으로만 느끼면 좋을 것 같습니다.
3.1 산 초입
- 대회 초반에는 데이터 EDA를 간단하게 하며 팀원 모두 Hugging face의 transforemrs 라이브러리 및 앞으로 사용하게 될 베이스라인의 리팩토링, 추가 기능 추가 등을 신경 썼습니다
- 다른 팀원들은 모르겠으나 저 같은 경우 저번 P-stage에 K-fold, Wandb 등을 활용하지 못한 것이 아쉬웠으나 이번 조에서는 그 부분을 일찍부터 활용 할 수 있어서 정말 만족했습니다.
- 또 기록을 남기기 위한 캠퍼들의 모임이니 하이퍼 패러미터, 실험 내용과 결과, 시도하고 있는 것들을 기록하는 페이지를 노션에 구축함으로 앞으로 있을 다양한 실험의 기초 토대를 마련했습니다.
- padding 방식도 fixed에서 dynamic padding으로 바꾸면서 모델 학습에 걸리는 시간을 약 30%를 단축 할 수도 있었습니다.
- 그 와중에 리더보드 1등을 운 좋게 달성해서 기분 삼아 스크린샷으로도 남겼습니다.

그래도 1등 한번 해봤으니 정상은 아니지만 사진 한번 찍어봤습니다. “김치~” “찰칵”
3.2 산 중턱
- 다른 팀들의 점수가 올라오는 와중에 벽으로 느껴졌던 F1 score 70을 넘는 팀들이 등장하기 시작했습니다.
- 이 와중에 저희 조 실험을 통해서 klue/roberta-large 모델을 통한 classification 모델을 사용하면 F1 score가 70을 넘을 수 있다는 사실을 깨달았습니다.
- 그것과 동시에 기존 입력
[CLS] 이순신 [SEP] 조선 [SEP] 이순신은 조선 중기의 무신이다. [SEP]의 input format에서[CLS] # * entity 1 map * 이순신#은 @ * entity 2 map * 조선 @ 중기의 무신이다. [SEP]와 같은 input format으로 변경하면 점수가 더 오르는 실험 결과도 얻을 수 있었습니다. - hugging face의 hp_search를 이용해서 모델 학습의 최적의 하이퍼 패러미터를 찾았습니다. 이 최적화된 하이퍼 패러미터로 F1 score를 약 2점가량 얻을 수 있었습니다.
- fp16 (16-bit Floating point)를 모델 학습에 사용함으로 성능은 비슷하되 학습 시간을 60%가량 향상된 속도로 모델 실험에 박차를 가 할 수 있었습니다. Roberta-large 기준 K-fold를 수행하면 대략 학습에 10시간 이상 걸리던 시간을 3~4시간 정도로 단축했습니다.
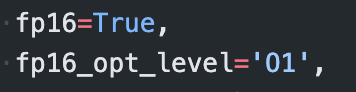
이거 정말 빠릅니다…. 스포츠카를 탄 느낌이었어요.
- 또 학습이 완료된 모델을 분석함으로 모델이 어떤 Label을 헷갈려 하는지, 어떤 데이터를 Augmentation 해야 하는지를 정했고 EDA, AEDA, Back Translation, subject object changing을 수행하여 data imbalance를 극복하고자 했습니다.
- 모델 자체의 실험도 진행했습니다. hugging face에서
AutoModelForSequenceClassification만을 사용하는 것이 아니라 label에 따라 model을 split 해보기도 하고 기존 모델들의 출력을 다시 이용하여 classification 하는 combine model, entity embedding을 이용하는 R-BERT, RE task에서 sota를 기록한 recent도 시도해보았습니다. - 다양한 Loss function도 도입해봤습니다. 단순 cross entropy 보다 imbalence data에 효과적이라는 CB loss, LDMA loss 를 도입했습니다.
- 또 TAPT를 통하여 MLM 모델에 Test data도 포함한 NLP data의 문장에 대한 확률 분포도 재학습해 봤습니다.
- 위의 모든 실험이 성과를 본 것은 아니었지만 2주가 짧은 시간, 그리고 딥러닝의 학습에 오랜 시간이 걸린다는 것을 생각해보면 많은 시도였다고 생각합니다. 이 모든 것이 기록과 공유를 통해 낭비 없는 실험을 한 덕분이라고 생각합니다.
3.3 정상 직전

- 저번 P-stage에서의 경험, 그리고 여러 Competition의 솔루션, 후기 등등을 읽으면서 느낀 것이 하나 있습니다. 바로 앙상블은 언제나 옳다는 것입니다. (가볍게 하는 말이니 사실이 아니더라도 너그럽게 봐주세요.)
- 저희 팀의 앙상블 전략은 크게 두 가지 였습니다.
- 좀 똘똘한 애들로 모아보자!
- 함께 문제를 풀더라도 머리 좋은 애들끼리 문제를 풀면 조금 더 좋은 성과가 있지 않겠습니까? 그래서 리더보드 기준으로 F1 score가 높은 모델들을 앙상블을 진행했습니다. 그 결과 F1 score는 public 리더보드 기준 74.306으로 9위로 마무리 할 수 있었습니다.
- 머리는 좋은데 공부를 안 한 애들을 모아보자!
- F1 score와는 상관 없이 AUPRC가 높은 모델들을 앙상블을 진행했습니다. 학습(공부)가 좀 덜되서 F1 score는 낮더라도 precision이나 recall이 적절하게 분배된 것이 아니라 한쪽으로 특화되었기 때문에 F1 score은 낮을지라도 AUPRC가 더 높지 않을까? 그 모델들을 앙상블 하면 안정된 precision이나 recall을 얻어 시너지를 낼 수 있지 않을까 싶어 시도한 전략입니다.
- 좀 똘똘한 애들로 모아보자!
3.4 하산

- public 기준으론 9등을 했습니다. 앙상블로 3등 올랐습니다.

- private 기준으로 5등입니다. AUPRC 기준 앙상블이어서 그런건진 몰라도 다른 팀보다 점수 하락 폭이 적었습니다. 무려 4등이나 올랐습니다.
- 하지만 점수로 나눈 등수보다 제출 횟수 99회(1등)가 더 뜻 깊게 다가옵니다. 이는 모두가 노력한 결과라고 생각합니다.
- 저희가 모일 때 한가지 다짐했던 게 있습니다. 앞만 보지 말고, 누군가의 등을 보지 않고, 서로서로 도와주며 함께 나아가자는 것입니다.
- 누군가 실력이 좋아서 그 사람만 의지했다면 제출 횟수가 저렇게 높지 않았을 것으로 생각합니다. 서로서로를 도와주며 함께 나아 갔기에 얻은 점수보다 소중한 제출 횟수입니다.
4. 훌륭한 이야기입니다. 그런데 님은 뭐 했어요?
살짝 반전이긴 한데 최종 기출 기준으로는 없어요. AUPRC 기준의 앙상블을 제가 하긴 했는데 그건 누군가 한 명이 코드 돌리기만 하면 됐던 일이라 딱히 제가 팀에 기여한 건 아니군요.
저희 팀원 모두가 훌륭한 분들이고 충분히 더 상위의 등수를 얻을 수 있었는데 못한 건… 네, 그렇습니다. 사실 제가 범인이었어요.

그래서 기여한 부분이 아니라 시도했던 부분을 설명해 보고자 합니다. 후술하겠지만 결론은 운이 없었고 그보다 실력이 더 없었어요.
4.1 이게 되네 ⁉
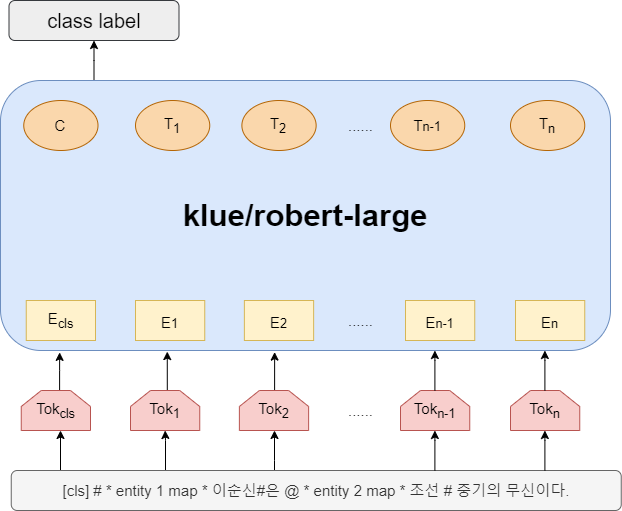
저희가 많이 사용하고 앙상블의 대부분을 담당했던 모델입니다.
- 위에도 설명했듯이 저희 조의 input format은 subject entity와 object entity에 대한 정보라고는 문장에 껴 넣은 punctuation marker와 entity map뿐입니다. 물론 사람이 보기에는 문장에 뜬금없이 저런 게 들어가 있고 몇 번 보다 보면 저렇게 표시된 단어들끼리의 상관관계를 알 수 있을지도 모릅니다.
- 딥러닝이 사람의 뇌가 학습하는 방법을 따라 했다는 것도 이제는 옛말이고 지금 와서는 거대한 비선형 근사식이 아니겠습니까? 과연 모델이 그냥 많은 문장들을 보면서 maker와 반복되어 나타나는 entity map을 보면서….

***”음 저건 subject entity군, 이건 object entity고 저기 로 표시된 건 entity의 type을 변환한 entity map이라 각 entity의 정보를 얻어 내는 데 도움이 되겠군. 그러니까 이러쿵저러쿵 해서 #으로 둘러 쌓인 것과 @로 둘러싸인 것의 관계는 이거네”**
라고 한다고요?!
물론 실험결과는 성능도 잘 나오긴 했는데 납득이 안가잖아요.
위대한 아인슈타인을 감히 제가 이해했다고 말하긴 죄송스럽지만, 양자역학을 거부한 심정이 이해가 갔습니다. 분명 양자역학은 양자들의 원리를 성공적으로 설명해냈지만 납득이 안가잖아요?! 저도 그랬습니다. 저 모델의 성능이 아무리 좋게 나와도 납득이 가지 않잖아요?

막상 배울땐 몰랐지만 비슷한 경험을 하고 나니까 조금은 이해할 수 있었습니다.
4.2 하라는 공부는 안하고! 😡
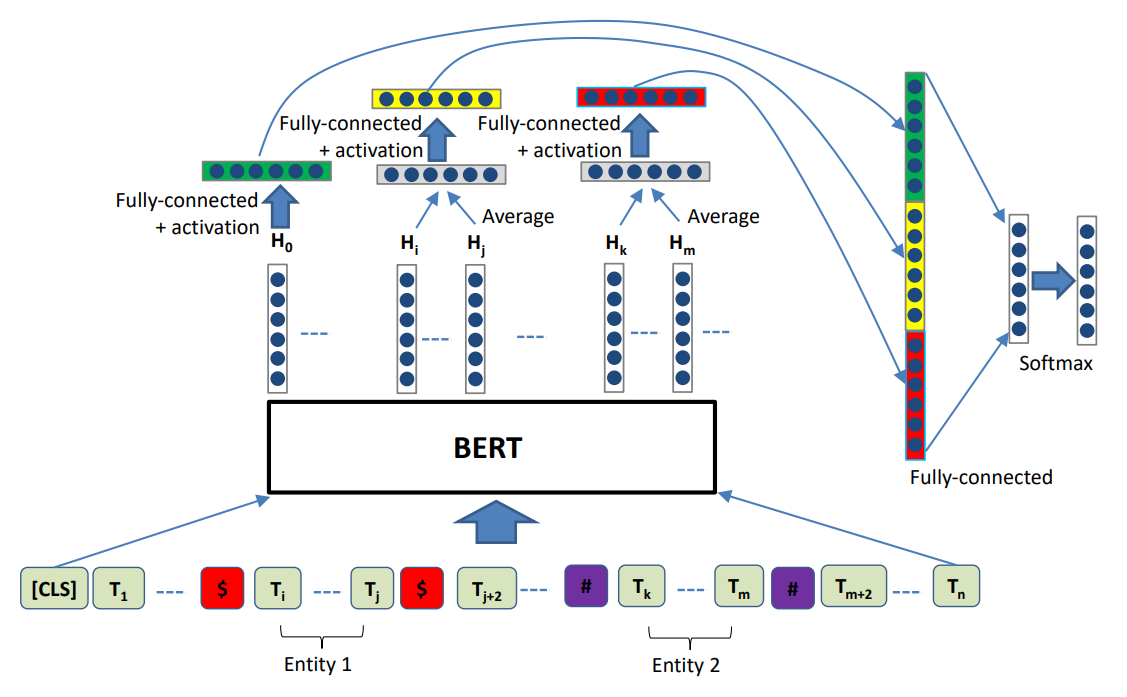
R-BERT
그래서 제가 찾은 모델 아키텍처는 R-BERT 였습니다.
저기 그림에 표현된 토큰들과 특수문자가 보이시나요? 딱 저희의 input 형식이 저런 형식이었잖아요? 게다가 추가로 entity mask를 사용해서 BERT의 output vector에 추가적인 entity는 무엇이라는 정보를 classification에 사용 할 수 있었습니다.
BERT 부분만 우리가 사용하는 Roberta로 바꾸면 완벽할 것만 같았습니다. entity 정보를 특수문자로만 학습하던 애가 특수문자 + entity mask까지 사용하면 당연히 성능이 올라야 하지 않겠습니까? 학원, 독서실 안 보내도 공부 잘하던 애를 학원, 독서실 보내면 성적이 더 올라서 전교 1등을 할 수 있다는 기대를 해도 되지 않겠습니까?
그리고 결과는…

당시 저희 조에서 성능을 내던 방식은 F1 score 72점 후반에서 73점 중반이었습니다. 그러니까 오히려 성능이 하락한 것이죠.
그러니까 공부하라고 학원, 독서실 보내놨는데 PC방에 가버린 꼴입니다.

사실 독서실 간다 하고 PC방가서 노는 게 몇 배는 더 재밌습니다. 저도 알아요.
그 후 R-BERT에서 더 이상 성능을 낼 수 없을 거라 예상하고 실험은 종료했습니다.
4.3 나는! 나는! 나는! 나는! R-BERT를 했다! 😇
https://www.youtube.com/watch?v=x7w7CeiyLEE&t=1130s
- 대회가 끝나고 1, 2위 팀의 솔루션과 추가 발표로 3위 팀의 솔루션을 들을 수 있었습니다.
- 여기서는 적지 않았으나 1, 2위 팀의 솔루션은 저희 팀에서 시도 했지만 실력, 시간등 복합적인 문제로 저희 조에 적용을 못시켰던 방법들 이었습니다. 살짝 아쉬웠습니다.
- 문제는 3등 팀의 솔루션이었습니다. 저희 조는 5등이었지만 3위 팀과는 0.13점 차이로 3, 4, 5 등 팀의 차이는 정말 한 끗차이었습니다. 헌데 3등 팀에서 사용했던 모델중에 R-BERT가 있다는 순간의 심정은 글로는 설명 못 할 것 같습니다.
- 앙상블은 보통 다양한 모델을 조합하면 성능이 좋아진다고 알려져 있었습니다. R-BERT의 실험이 성공적이어서 저희 조 앙상블 모델에 R-BERT가 추가되었더라면 0.13 차이는 물론이고 더 위도 어쩌면 가능하지 않았을까? 라는 생각이 드는건 어쩔 수가 없었습니다.
- 4챕터를 쓰면서 운이 살짝 없었다고 적긴 했지만 다시 생각해보면 운은 상관 없고 그냥 저의 실력 부족, 그러니까 실험을 제대로 하지 않은 탓이라고 생각이 드네요. 저 자신에게 크게 실망했습니다.
- 나름 실험을 꼼꼼하게 한다고 했는데 충분하지 않았습니다. 대회 마지막 가서는 성능을 내야 한다는 조급한 마음에 이도 저도 안됐던 것 같습니다. 다른 팀원 분들에게 미안할 따름입니다.
5. 다음 목적지 🏔
- 바로 MRC 대회가 열리기 때문에 자책하는 것은 그만두고 빠르게 재정비해서 MRC 대회에 임해야겠다고 생각했습니다.
- 아쉬운 것은 아쉬운 거고 앞으로 더 잘하면 되지 않겠어요?
- 그래도 두 번의 P-stage를 경험하면서 계속 성장하고 있다는 게 느껴져서 다음에는 더 잘 할 수 있을 거라고 생각하고 있습니다.
- 그런 의미로 1등 조원 한분께 다음 대회는 각오하세요. 1등 하겠습니다. 라고 말은 했습니다 99% 농담이지만요. 헌데 그분이 웃으시면서 “같이 성장해 나가요.” 라는 답변을 들었는데 눈부셔서 바라볼 수도 없었습니다.

사실 이렇게 보였을지도 모릅니다. ㅋㅋ
- 최종 결론은 다음 P-stage도 성장하고 싶습니다. 혼자 아니라 팀원, 캠퍼 모두하고 함께 성장했으면 좋겠습니다.